
KI macht Softwareprojekte schneller – und verschiebt das Risiko an eine Stelle, die klassische Entwicklungsprozesse selten kontrollieren. Eine Untersuchung von Veracode über mehr als 100 Sprachmodelle zeigt: 45 % des generierten Codes führt mindestens eine Schwachstelle aus den OWASP Top 10 ein, und diese Quote stagniert seit zwei Jahren – trotz spürbar besserer Syntax (Veracode GenAI Code Security Report).
Das Ziel ist nicht, KI zu vermeiden. In Deutschland setzen laut Bitkom inzwischen 36 % der Unternehmen KI ein – fast doppelt so viele wie ein Jahr zuvor. Das Ziel ist, KI so zu kontrollieren wie jede andere produktive Abhängigkeit: mit klaren Regeln, Verantwortlichkeiten und technischen Leitplanken.
Wo die echten Risiken entstehen – nicht im Tool
KI-Risiken entstehen selten durch ein einzelnes Tool – sie entstehen durch fehlende Grenzen, fehlende Tests und fehlende Verantwortung. Die nüchternen Zahlen helfen, das Bauchgefühl zu schärfen. Veracode ließ über 100 Modelle 80 Coding-Aufgaben lösen und prüfte das Ergebnis gegen die OWASP Top 10: 45 % der Lösungen waren unsicher, bei Java lag die Durchfallquote sogar bei 72 %, bei Cross-Site-Scripting und Log Injection über 85 %.
Ein zweites Risiko ist subtiler. Eine an der USENIX Security 2025 vorgestellte Studie zu Paket-Halluzinationen generierte 2,23 Millionen Code-Samples – 19,7 % enthielten mindestens ein Paket, das gar nicht existiert. Angreifer registrieren diese erfundenen Namen vorab in npm oder PyPI („Slopsquatting"). Wer KI-Vorschläge ungeprüft übernimmt, holt sich so im schlimmsten Fall fremden Code in die Lieferkette.
Die Lehre ist nicht „KI schreibt schlechten Code", sondern: KI-Output ist ein Vorschlag, kein fertiges Ergebnis. Genau dafür braucht es Reviews, Tests und klare Regeln – so, wie wir es in einem Code-Audit ohnehin tun.
Fünf Risikokategorien, die klassische Prozesse übersehen
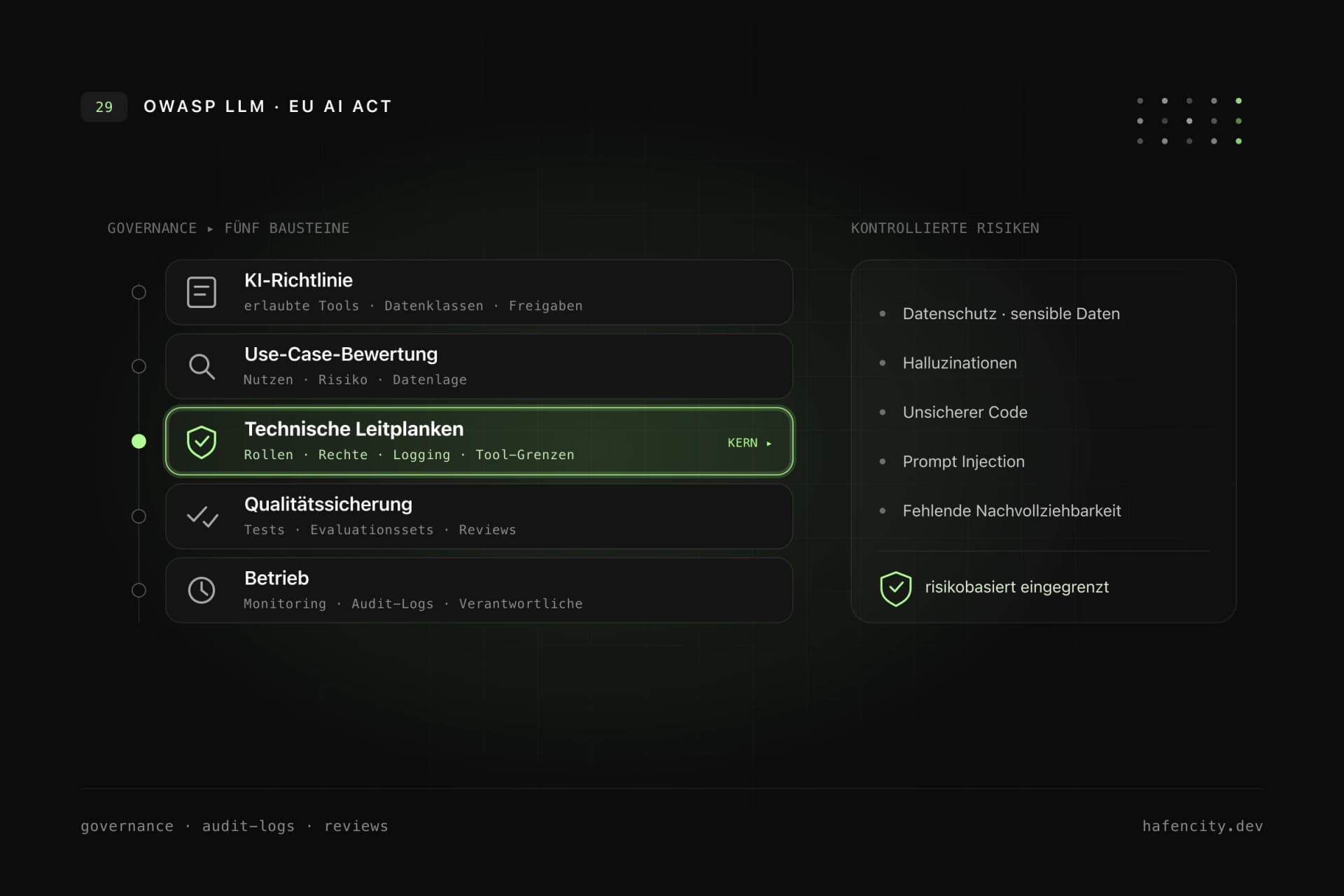
Die meisten KI-Vorfälle lassen sich fünf Kategorien zuordnen – und jede hat eine konkrete Gegenmaßnahme. Wer diese fünf Felder systematisch abdeckt, verwandelt diffuse „KI-Angst" in ein steuerbares Risikoprofil.
| Risikokategorie | Was passiert | Gegenmaßnahme |
|---|---|---|
| Datenschutz | Logs, Kundendaten, Schemas landen in externen Tools | Datenklassen, Anonymisierung, EU-Hosting, klare Freigaben |
| Halluzinationen | erfundene APIs, Pakete, falsche Versionen | Quellen referenzieren, Tests verlangen, gegen Doku abgleichen |
| Unsicherer Code | breite Rechte, fehlende Fehlerbehandlung, schwache Typen | architekturbewusster Review, Secret-Schutz, Edge-Case-Tests |
| Prompt Injection | versteckte Anweisungen in Inhalten oder Anfragen | harte Tool-Grenzen, Freigaben, Eingabe- und Ausgabefilter |
| Nachvollziehbarkeit | niemand weiß, was das System sah und warum | Audit-Logs, Prompt-Versionierung, Monitoring, Freigabehistorie |
Wichtig ist die Reihenfolge: Datenschutz und Nachvollziehbarkeit sind Architekturentscheidungen, die an den Anfang gehören – nicht etwas, das man kurz vor dem Launch nachrüstet.
Prompt Injection: das neue Angriffsmodell für KI-Agenten
Sobald ein KI-System externe Inhalte liest oder Tools nutzt, entsteht eine Angriffsfläche, die es in klassischer Software so nicht gibt. Ein Dokument, eine Website oder eine Nutzeranfrage kann versteckte Anweisungen enthalten, die das Modell zu unerwünschtem Verhalten bringen. In den OWASP Top 10 für LLM-Anwendungen 2025 steht Prompt Injection auf Platz 1 (LLM01) – nicht zufällig, denn aufgrund der stochastischen Natur der Modelle gibt es kein narrensicheres Gegenmittel.
Praktisch heißt das: Ein KI-Agent darf nicht automatisch alles tun, nur weil ein Dokument es behauptet. Wirksam ist Verteidigung in mehreren Schichten – Eingabevalidierung, Ausgabefilter, eingeschränkte Rechte und menschliche Freigabe für sensible Operationen. Je mehr Tool-Zugriff ein Agent hat, desto enger müssen die Leitplanken sein. Wie das in produktiven KI-Agenten im Unternehmen aussieht, hängt direkt davon ab, welche Aktionen reversibel sind und welche nicht.
EU AI Act: risikobasiert – und der Zeitplan hat sich 2026 verschoben
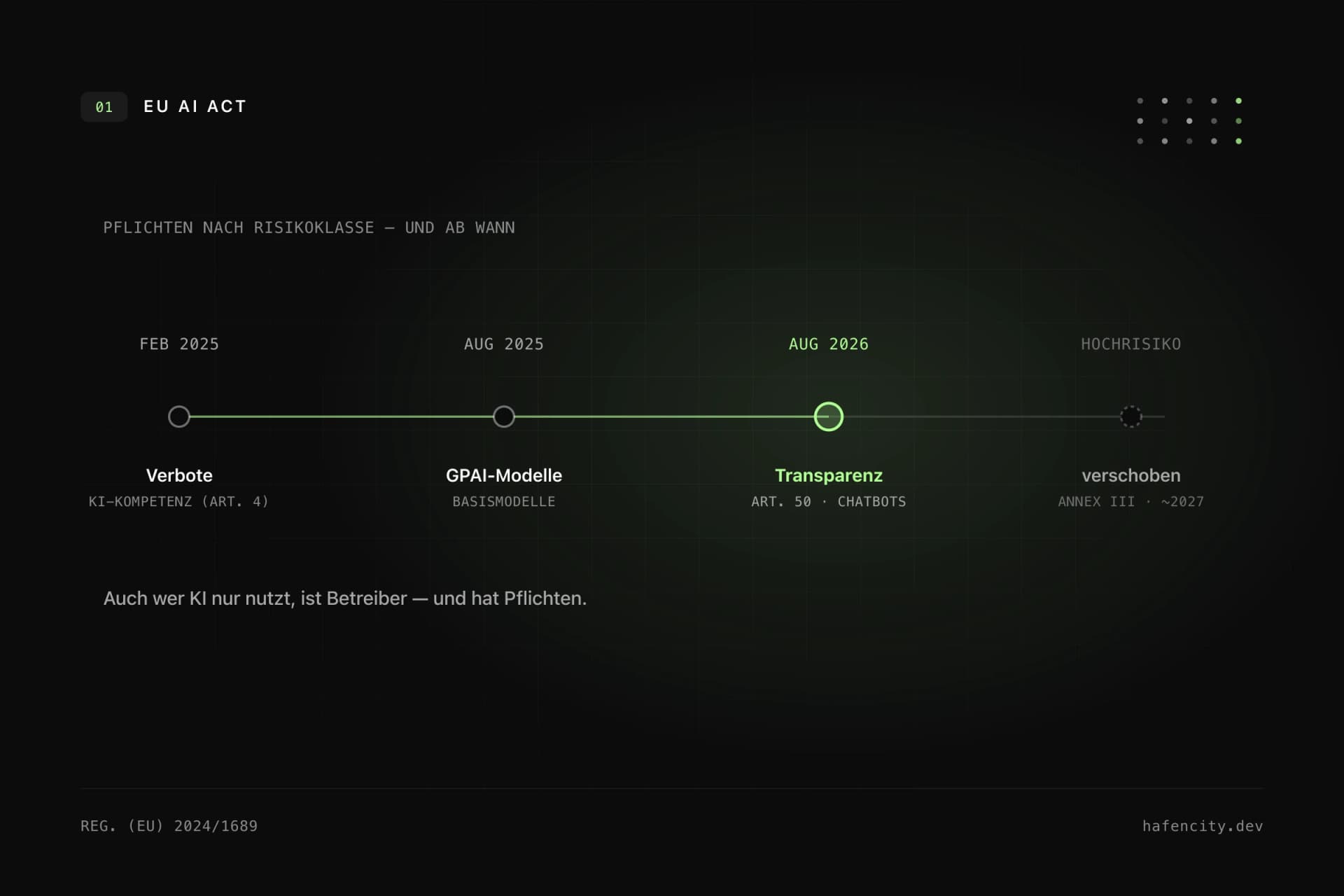
Der EU AI Act folgt einem risikobasierten Ansatz: Nicht jede KI-Anwendung hat dieselben Pflichten. Ein internes Tool zur Code-Zusammenfassung ist anders zu bewerten als ein System, das Bewerbungen filtert, Kreditentscheidungen vorbereitet oder medizinische Empfehlungen gibt. Und der Zeitplan hat sich 2026 spürbar bewegt: Mit dem Digital Omnibus – einer vorläufigen Einigung von Rat und Parlament vom 7. Mai 2026 – werden die Hochrisiko-Pflichten verschoben.
Konkret: Die Pflichten für eigenständige Hochrisiko-Systeme nach Anhang III (u. a. Recruiting, Kreditvergabe, Bildung) verschieben sich von August 2026 auf Dezember 2027, für KI in regulierten Produkten nach Anhang I auf August 2028 (Übersicht der Fristen). Die GPAI-Regeln gelten seit August 2025, die Transparenzpflichten bleiben weitgehend auf dem ursprünglichen Plan. Für Unternehmen ändert die Verschiebung wenig am Prinzip: Welchen Zweck hat das System, wer ist betroffen, werden Entscheidungen automatisiert, gibt es menschliche Freigabe? Diese Einordnung gehört an den Anfang, nicht kurz vor den Launch.
Governance, die nicht bürokratisch ist
KI-Governance muss nicht schwerfällig sein – sie muss praktikabel sein. Ein guter Start besteht aus fünf Bausteinen: einer KI-Richtlinie (erlaubte Tools, Datenklassen, Freigaben), einer Use-Case-Bewertung vor der Umsetzung, technischen Leitplanken (Rollen, Rechte, Logging, Tool-Grenzen), Qualitätssicherung (Tests, Evaluationssets, menschliche Reviews) und einem definierten Betrieb (Monitoring, Fehleranalyse, Verantwortliche).
Auf der technischen Ebene gilt für KI dasselbe wie für jedes produktive System – nur mit ein paar zusätzlichen Regeln:
- keine Secrets in Prompts, serverseitige Tool-Ausführung mit Rechteprüfung
- getrennte Umgebungen für Entwicklung und Produktion
- Eingabe- und Ausgabevalidierung, Rate- und Kostenlimits
- Logging ohne unnötige personenbezogene Daten
- menschliche Freigabe für irreversible Aktionen
- Tests gegen Prompt Injection und unerlaubte Tool-Nutzung
Lokale oder private Modelle sind nicht für jedes Projekt nötig, aber sinnvoll, wenn Daten das Unternehmen nicht verlassen sollen oder branchenspezifische Compliance strenge Anforderungen stellt – etwa bei interner Wissenssuche, Vertragsanalyse oder sensiblen Produktdaten. Wie wir das mit Datenschutz und Betrieb zusammendenken, zeigt unsere KI-Integration.
Nächste Schritte
Drei Fragen zeigen schnell, wie groß dein KI-Risiko heute wirklich ist:
- Daten: Weißt du, welche Daten in welche Tools fließen – und welche das Unternehmen nicht verlassen dürfen?
- Code & Agenten: Wird KI-Output reviewt, getestet und an harten Tool-Grenzen begrenzt, bevor er Produktion erreicht?
- Verantwortung: Gibt es für jedes KI-System eine klare Einordnung, Audit-Logs und eine zuständige Person?
Wo du zögerst, lohnt der genauere Blick. Wir behandeln KI-Projekte als Softwareprojekte mit besonderen Anforderungen – pragmatisch, mit Blick auf Roadmap und Budget. Sieh dir unsere KI-Integration an oder buche direkt ein Erstgespräch.