
Viele Softwareunternehmen behandeln SEO noch immer wie eine Content-Aufgabe: Keywords recherchieren, Blogartikel schreiben, Meta-Titles optimieren. Das ist nicht falsch, aber unvollständig – und 2026 riskanter als je zuvor. Denn die Suche hat sich verschoben: Laut Pew Research erschien im März 2025 bei rund 18 Prozent aller Google-Suchen eine KI-Zusammenfassung, und wenn sie auftaucht, klicken Nutzer nur noch in 8 Prozent der Fälle auf einen klassischen Treffer – ohne KI-Antwort sind es fast doppelt so viele (15 Prozent).
Wer in diesem Umfeld gefunden – oder von einer KI-Antwort als Quelle zitiert – werden will, braucht mehr als die richtigen Wörter. Eine Produktseite kann ein Problem perfekt erklären, eine Doku exakt die Fragen vor der Integration beantworten. Wenn diese Seiten aber nicht crawlbar sind, falsche Canonicals setzen oder zu langsam laden, bleibt ihr Potenzial liegen. Technische SEO ist deshalb kein nachgelagerter Check, sondern Teil der Produkt- und Website-Architektur.
Keywords zeigen die Sprache – nicht den Weg
Keywords beschreiben, wie ein Markt sucht, aber sie sorgen nicht dafür, dass eine Seite überhaupt ausgespielt wird. Für Softwareunternehmen ist die Suchintention vielschichtig: Das Management sucht nach Ergebnissen, Kosten und Risiko, Product Owner nach Use Cases und Integrationen, Entwickler nach API-Dokumentation, SDKs, Webhooks und Limits, Compliance-Teams nach Datenschutz, Rollen und Zertifizierungen. Diese Intentionen in eine robuste Seitenstruktur zu übersetzen, ist die eigentliche Arbeit – nicht das Zählen von Wörtern.
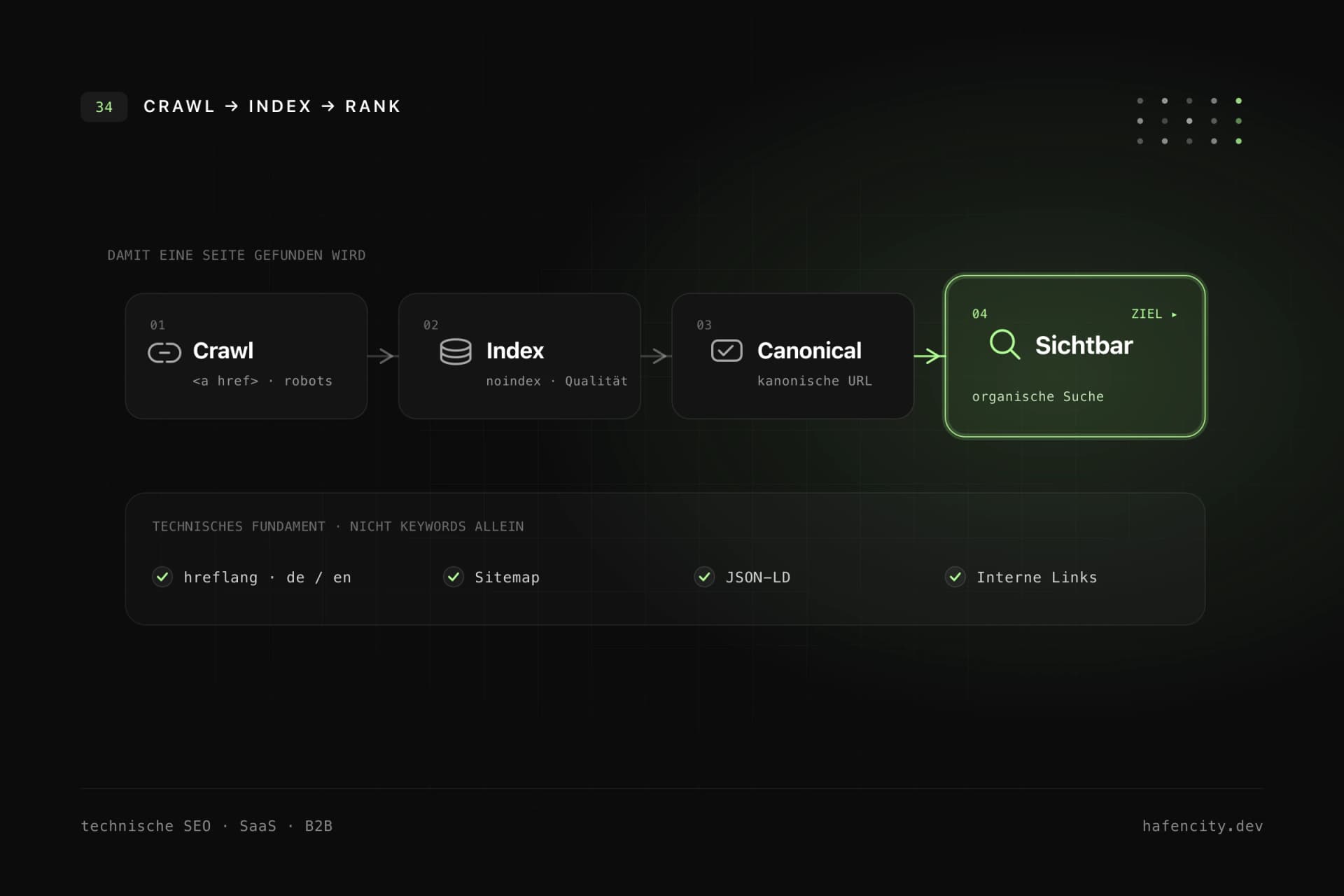
Davor steht aber eine technische Kette, die jedes Keyword voraussetzt. Eine Seite muss gefunden (gecrawlt), korrekt aufgebaut (gerendert), in den Index aufgenommen (indexiert) und schließlich bewertet (gerankt) werden, bevor sie überhaupt eine Chance hat – inzwischen auch darauf, in einer KI-Antwort als Quelle zitiert zu werden. Reißt die Kette an einer Stelle, hilft die beste Keyword-Recherche nicht.
Was sich an dieser Kette zuletzt verändert hat, ist mehr als kosmetisch. Drei Punkte verschieben die Prioritäten für Softwareteams konkret:
| Thema | Früher | Heute (Juni 2026) | Quelle |
|---|---|---|---|
| Reaktions-Metrik der CWV | FID | INP < 200 ms (seit März 2024) | web.dev |
| FAQ-Rich-Results | sichtbar in der Suche | komplett entfernt | |
| Klick auf Treffer bei KI-Antwort | 15 % | 8 % | Pew Research |
Crawlability und Indexability: erreichbar ist nicht gleich indexiert
Crawling und Indexierung sind zwei getrennte Schritte – und beide gehen bei modernen Software-Websites schnell schief. Crawlability beschreibt, ob Suchmaschinen eine Seite finden und abrufen können. Bei JavaScript-lastigen Frontends, Filtern, dynamischen Routen oder Headless-CMS-Setups ist das keine Selbstverständlichkeit: Wenn Pricing, Docs oder Integrationsseiten nur über clientseitige Events erreichbar sind oder Links als div- oder Button-Elemente statt als echte <a href>-Links umgesetzt werden, kann die Sichtbarkeit unnötig leiden. Google weist in seinen Link-Best-Practices ausdrücklich darauf hin, dass Links als a-Elemente mit href crawlbar sein sollten.
Indexability ist die strategische zweite Frage: Soll diese URL überhaupt in den Index? Crawlbar zu sein bedeutet nicht automatisch, indexiert zu werden – noindex, widersprüchliche Canonicals, Duplikate oder dünne Inhalte verhindern das. Indexierbar sein sollten vor allem Seiten mit eigenständigem Suchwert: Produkt-, Feature-, Use-Case-, Integrations- und Vergleichsseiten, öffentliche Dokumentation, API-Referenzen, Guides und Case Studies. Interne Suche, Account-Bereiche, dünne Filtervarianten, Kampagnen- und Preview-URLs gehören meist bewusst nicht hinein. Diesen Unterschied bewusst zu modellieren ist die halbe Miete – mehr dazu in unserer SEO-ohne-Verlust-Checkliste für Relaunches.
Canonicals, hreflang und strukturierte Daten: Eindeutigkeit für Maschinen
Software-Websites produzieren Duplikate fast automatisch – Canonicals, hreflang und strukturierte Daten machen daraus eine eindeutige Karte. /pricing, /de/pricing, Tracking-Parameter, sortierte Listen, Kampagnenvarianten und Doku-Versionen erzeugen ähnliche URLs. Google beschreibt Canonicalization als Auswahl der repräsentativen URL einer Gruppe – trifft man die Wahl nicht selbst, übernimmt Google sie, mitunter abweichend. Drei pragmatische Regeln: Jede indexierbare Seite bekommt ein selbstreferenzierendes Canonical, Duplikate zeigen auf die Haupt-URL, und Canonicals, Redirects, Sitemaps und hreflang dürfen sich nicht widersprechen.
Mehrsprachigkeit verschärft das. Wer Deutsch und Englisch ausspielt, sollte hreflang ins Routing legen: Jede Version verweist auf sich selbst und auf die anderen, und zwar auf kanonische URLs. Googles Hinweise zu lokalisierten Versionen sind hier eindeutig. Strukturierte Daten schließlich machen die Bedeutung explizit – Google empfiehlt JSON-LD. Wichtig 2026: Die FAQ-Rich-Results sind im Juni vollständig aus der Suche verschwunden, inklusive der früheren Ausnahme für Behörden- und Gesundheitsseiten. FAQPage-Markup schadet nicht, bringt aber keine sichtbaren Snippets mehr. Lohnend bleiben Organization, Article/BlogPosting, BreadcrumbList und – wo die Anforderungen erfüllt sind – Product oder SoftwareApplication.
Performance ist Produktqualität, nicht ein Ranking-Trick
Performance entscheidet, ob Nutzer Inhalte sehen, interagieren können und auf mobilen Geräten bleiben – und sie ist ein offizielles Page-Experience-Signal. Die Core Web Vitals fassen das in drei messbaren Werten zusammen. Seit März 2024 misst INP (Interaction to Next Paint) die Reaktionsfähigkeit und hat die ältere Metrik FID abgelöst.
Typische Baustellen bei SaaS-Sites sind unoptimierte Hero-Bilder und Screenshots, schwere JavaScript-Bundles aus Marketing-Tools, clientseitig gerenderte Inhalte ohne saubere Server- oder Pre-Rendering-Strategie sowie blockierende Fonts und Consent-Skripte. Es lohnt sich, Marketing-Website, Docs und App technisch zu trennen: Eine öffentliche Doku muss nicht dieselbe JavaScript-Last tragen wie ein eingeloggtes Produkt. Wie sich diese Werte gezielt verbessern lassen, zeigen wir in Core Web Vitals & Performance-Optimierung.
Content-Architektur und interne Verlinkung: Struktur sichtbar machen
Softwareunternehmen haben selten zu wenig Inhalt – sie haben eine zerstreute Architektur. Produktseiten, Feature-Seiten, Use-Case-Seiten, Dokumentation, API-Referenzen, Blogartikel und Case Studies erfüllen unterschiedliche Rollen und sollten nicht gegeneinander konkurrieren. Ein Blogartikel über Webhook-Best-Practices ersetzt keine API-Referenz, eine API-Referenz keine verständliche Integrationsseite, eine Feature-Seite keine Case Study. Gute technische SEO macht diese Rollen klar und verbindet sie sinnvoll.
Interne Links sind die Verbindung zwischen Content-Strategie und Technik. Feature-Seiten verlinken zu passenden Docs und Use Cases, Vergleichsseiten zu Migrationsguides und Integrationen, Case Studies zu den gelösten Problemen statt nur zur Startseite. Entscheidend sind beschreibende Ankertexte: „API-Rate-Limits verstehen" hilft Nutzern und Maschinen mehr als „hier klicken". Gerade weil KI-Antworten Inhalte zusammenfassen und zitieren, zahlt eine klare, gut verlinkte Architektur doppelt ein – sie macht es Crawlern und Modellen leicht, die richtige Seite als Quelle zu erkennen.
Was ein technischer SEO-Audit für Softwareteams prüfen sollte
Ein sinnvoller Audit prüft nicht nur Titles und Keywords, sondern verbindet Website-Technik, CMS, Routing und Content-Modell. Eine pragmatische Checkliste:
- Sind alle strategisch wichtigen Seiten crawlbar und über echte
<a href>-Links erreichbar? - Welche Seiten sind indexierbar, welche bewusst
noindexoder blockiert? - Stimmen Canonicals, Redirects, Sitemaps und hreflang überein?
- Sind strukturierte Daten valide und decken sie nur das, was Nutzer sehen?
- Erzeugen Parameter, Filter oder Kampagnen URL-Duplikate?
- Liegen LCP, INP und CLS im grünen Bereich – auch mobil?
- Werden organisch wichtige Inhalte server- oder vorgerendert ausgeliefert?
Der wichtigste Punkt: Technische SEO sollte wiederholbar im Entwicklungsprozess verankert sein. Neue Seiten, Sprachen, Docs-Versionen und Kampagnen dürfen die Suchstruktur nicht jedes Mal zufällig verändern. Wie ein strukturierter Audit Technik, Performance und Barrierefreiheit zusammen misst, beschreiben wir in Qualität ist messbar.
Nächste Schritte
Drei Fragen klären schnell, wo dein Software-Produkt technisch steht:
- Crawling & Index: Sind alle wichtigen Seiten über echte Links erreichbar – und ist bewusst geregelt, was indexiert wird und was nicht?
- Performance: Liegen LCP, INP und CLS im grünen Bereich, auch auf dem Smartphone?
- Architektur: Sind Docs, Blog, Produkt- und Referenzseiten zu klaren Clustern verbunden, die Suchmaschinen und KI-Antworten als Quelle erkennen?
Unsicher, wo die Lücken liegen? Wir bauen technische SEO als festen Teil der Entwicklung mit – pragmatisch und messbar. Sieh dir unsere Web-Entwicklung an oder buche direkt ein Erstgespräch.