
KI im Unternehmen ist 2026 kein Pilotthema mehr: Laut der Bitkom-KI-Studie 2026 setzen 41 Prozent der Unternehmen ab 20 Beschäftigten KI aktiv ein, weitere 48 Prozent planen oder diskutieren den Einsatz. Der häufigste Wunsch dahinter lautet „ChatGPT mit unseren eigenen Daten“. Gemeint ist meist kein allgemeiner Chatbot, sondern ein System, das interne Dokumente, Wikis, Produktinfos und Supportdaten durchsucht und daraus nachvollziehbare Antworten erzeugt. Technisch heißt der Ansatz Retrieval-Augmented Generation (RAG).
Der Abstand zwischen einer Demo und einem produktiven System ist allerdings groß. Eine Demo beantwortet Fragen aus ein paar PDFs. Ein produktiver Unternehmens-Chatbot muss wissen, welche Daten ein Nutzer sehen darf, wann er unsicher ist, wie Quellen zitiert werden und wie Qualität dauerhaft gemessen wird.
Demo oder Produktivsystem: der teure Unterschied
Sehr unterschiedliche Systeme werden alle „KI-Chatbot“ genannt – und genau hier entstehen die meisten Fehlentscheidungen. Für eine öffentliche Website-FAQ reicht oft ein Standardtool. Für Unternehmenswissen mit Berechtigungen, SSO, sensiblen Daten und mehreren Systemen braucht es eine andere Architektur. Der häufigste teure Fehler ist, mit einem einfachen Demo-Bot zu starten und ihn später unkontrolliert auf sensible Daten loszulassen.
| Typ | Geeignet für | Grenzen |
|---|---|---|
| Website-FAQ-Bot | öffentliche Fragen, Helpcenter, einfache Lead-Qualifizierung | wenig Rechte, einfache Quellen |
| Interner Wissensbot | Policies, Onboarding, Prozesswissen, Produktdoku | braucht Datenpflege, Rollen, Quellenverantwortung |
| Support-RAG-Bot | Tickets, Produktdoku, Fehlerdatenbank, Antwortvorschläge | braucht Qualitätssicherung und menschliche Freigabe |
| Kundenportal-Assistent | kundenspezifische Dokumente, Status, Verträge | braucht strikte Mandantentrennung |
| Agentischer Workflow | Chatbot plus Aktionen in CRM, Ticketing, ERP | braucht Tool-Grenzen, Audit-Logs, Freigaben |
Die ehrliche Frage vor dem Start ist nicht „welches Modell?“, sondern: Welche Datenquellen, welche Berechtigungen, welcher konkrete Frage-Antwort-Prozess? Wer das klärt, baut kein KI-Experiment, sondern ein Produkt.
Wie permission-aware RAG funktioniert
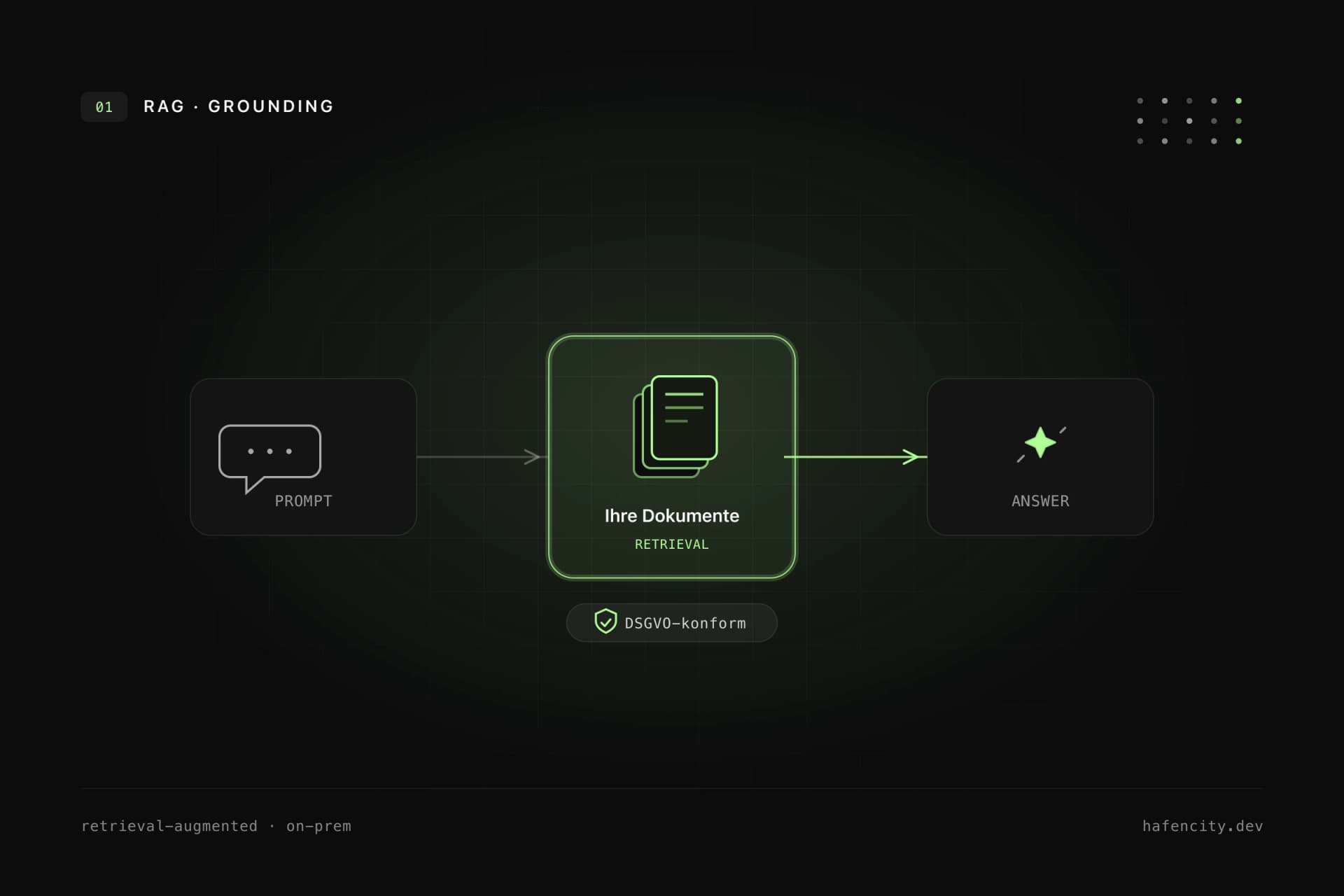
In Unternehmen ist der wichtigste Architekturpunkt nicht der Prompt, sondern die Frage, welche Daten überhaupt in den Modellkontext gelangen dürfen. RAG sucht zuerst relevante Informationen und lässt das Sprachmodell dann auf Basis dieses Kontexts antworten. Der kritische Schritt liegt zwischen Suche und Antwort: die Rechteprüfung.
Ein permission-aware System prüft vor jeder Antwort, wer der Nutzer ist, zu welcher Organisation oder Rolle er gehört und welche Dokumente, Tickets oder Datensätze er sehen darf – inklusive Rechten aus SharePoint, Google Drive, CRM oder einem eigenen Backend. Diese Prüfung gehört ins Backend und muss für jede Anfrage gelten, nicht nur beim Login. Gerade bei Kundenportalen, HR-, Vertrags- oder Finanzdaten ist das der Unterschied zwischen Demo und Produktion. Gelangt ein nicht autorisierter Abschnitt einmal an das Modell, ist die Zugriffskontrolle bereits gescheitert. Wie wir solche Systeme bauen, zeigt unsere KI-Integration.
Datenquellen: womit der Pilot startet
Die Datenquellen bestimmen die Qualität stärker als das Modell. Nicht jede Quelle eignet sich für den Start. Gute erste Quellen sind aktuell, fachlich geprüft, klar verantwortet und wenig sensibel. Schlechte erste Quellen sind riesige Ordnerstrukturen mit alten, widersprüchlichen oder unberechtigten Dokumenten.
| Datenquelle | Eignung für Pilot | Warum |
|---|---|---|
| gepflegtes Helpcenter | hoch | klare Inhalte, häufige Fragen, guter Quellenbezug |
| Produktdokumentation | hoch | gut strukturierbar, hoher Nutzen für Support und Sales |
| interne Prozesshandbücher | mittel bis hoch | hilfreich, wenn aktuell und verantwortlich gepflegt |
| SharePoint/Drive mit Altdateien | niedrig bis mittel | braucht Bereinigung, Metadaten, Rechteprüfung |
| CRM- und Ticketdaten | mittel | nützlich, aber personenbezogen und rechteabhängig |
| Verträge und HR-Dokumente | vorsichtig | hohe Sensibilität, klare Rollen und Freigaben nötig |
Ein guter Pilot startet nicht mit „alle Daten“, sondern mit einer wertvollen, kontrollierbaren Quelle und einem klaren Fragetyp. Für den produktiven Betrieb kommen Synchronisation, Änderungsverfolgung, Duplikaterkennung und klare Datenverantwortliche dazu. Mehr dazu in KI-Use-Cases realistisch starten.
Datenschutz, EU AI Act und Sicherheit
Bei Unternehmens-Chatbots geht es fast immer um personenbezogene oder vertrauliche Daten – Governance ist deshalb Teil der Architektur, nicht ein Anhang. Technisch sollten früh klare Antworten stehen: Welche Quellen enthalten personenbezogene Daten? Welche Inhalte dürfen an Modellanbieter gehen? Wo liegen Prompts, Antworten, Logs und Embeddings, wie lange, und wer kann sie einsehen?
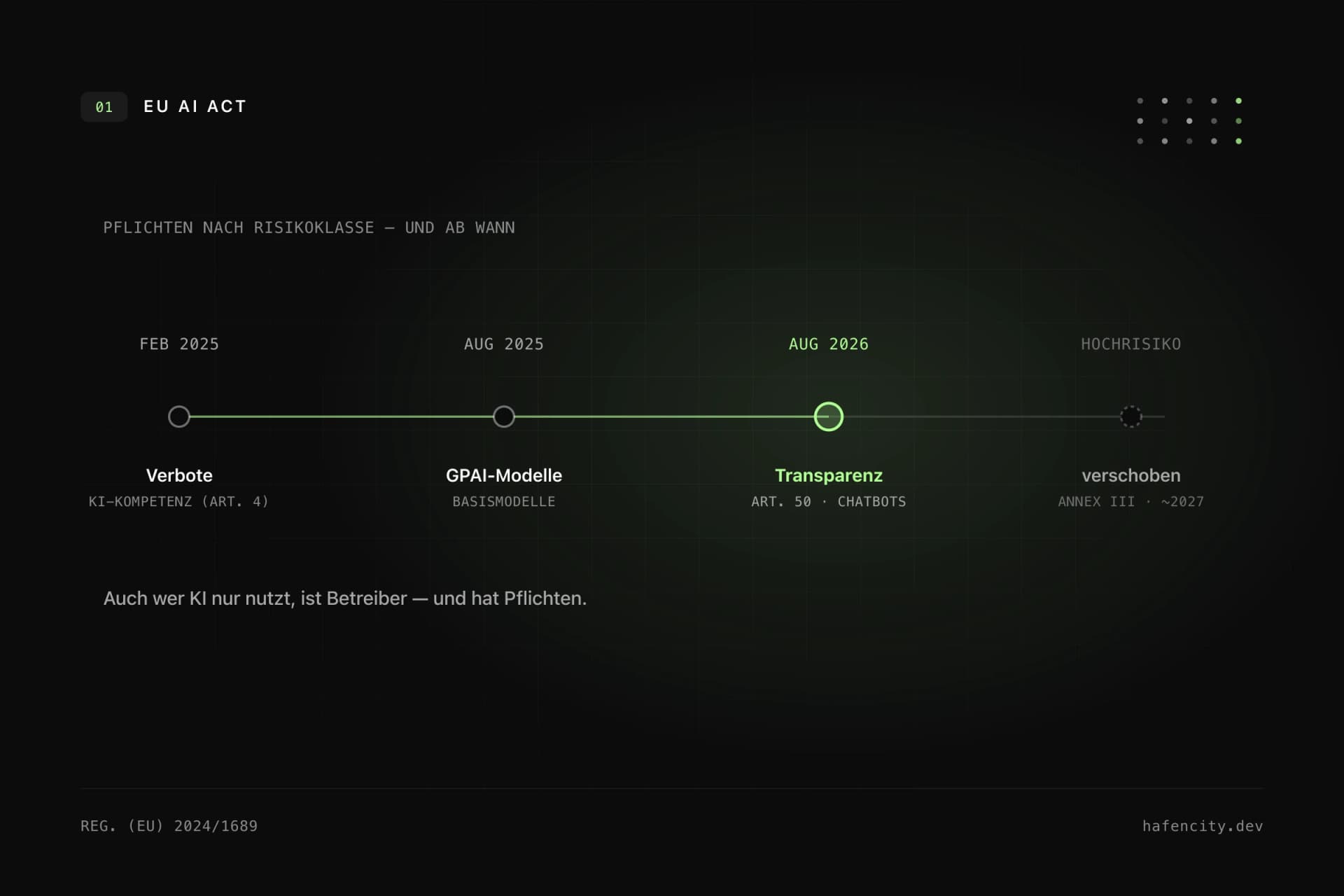
Der EU AI Act ist seit dem 1. August 2024 in Kraft und wird gestaffelt anwendbar. Für Chatbots zählt vor allem Artikel 50: Die Transparenzpflichten gelten ab dem 2. August 2026 – Nutzer müssen klar erkennen, dass sie mit einem KI-System sprechen. Mit dem Ende 2025 vorgeschlagenen Digital Omnibus haben sich Gesetzgeber im Mai 2026 darauf geeinigt, die Pflichten für Hochrisiko-Systeme nach Anhang III von August 2026 auf den 2. Dezember 2027 zu verschieben. Die meisten internen Wissens-Chatbots sind keine Hochrisiko-Systeme, brauchen aber Transparenz, Zweckbindung, Risikobewertung und Dokumentation.
Sicherheit ist ein eigenes Thema. Sobald ein Chatbot externe Inhalte liest oder Aktionen auslöst, kann ein Dokument oder eine Nutzerfrage versteckte Anweisungen enthalten. In den OWASP Top 10 für LLM-Anwendungen (2025) steht Prompt Injection auf Platz 1; neu bewertet werden Schwächen in Vektor- und Embedding-Systemen, die für RAG besonders relevant sind. Praktische Gegenmaßnahmen: Systemanweisung, abgerufene Inhalte und Nutzereingabe klar trennen, Tool-Aufrufe serverseitig begrenzen und validieren, keine Secrets in Prompts oder Logs, und irreversible Aktionen nur mit menschlicher Freigabe. Ein RAG-Chatbot wird sicherer, wenn er weniger darf – mehr dazu in Risiken in KI-Softwareprojekten.
Kosten und Fahrplan: Pilot vor Produktion
Ein KI-Chatbot sollte in Stufen gebaut werden – der Pilot beantwortet, ob Datenlage und Nutzen tragfähig sind, bevor in Rollen, SSO und Betrieb investiert wird. Die folgenden Korridore sind unsere typischen Projektgrößen, keine Listenpreise; die tatsächliche Zahl hängt von Quellen, Integrationen und Compliance-Tiefe ab.
| Projekttyp | Realistischer Korridor | Was enthalten ist |
|---|---|---|
| Daten- und Use-Case-Check | 5.000–15.000 EUR | Use Case, Quellen, Datenschutz, Erfolgsmetriken |
| RAG-Prototyp | 20.000–60.000 EUR | eine Quelle, einfache Oberfläche, Quellenantworten |
| Pilot mit echten Nutzern | 40.000–100.000 EUR | Nutzergruppe, Evaluation, erste Rechteprüfung |
| Produktiver Unternehmens-Chatbot | 60.000–180.000 EUR und mehr | Rollen, SSO, Integrationen, Monitoring, Betrieb |
Dazu kommen laufende Kosten. Sie sind oft kleiner als gedacht: Embeddings kosten bei OpenAI mit text-embedding-3-small rund 0,02 $ je Million Tokens, die laufenden Treiber sind eher Modellaufrufe pro Antwort, Vektordatenbank, Hosting, Monitoring und Daten-Synchronisation. Wichtiger als der Einstiegspreis ist, ob Antwortqualität messbar bleibt: gepflegte Quellen, Retrieval-Tests, Quellenangaben, Refusal-Verhalten bei Unsicherheit und ein Evaluationsset. Ein produktiver Chatbot sollte sagen können: „Dazu finde ich in den freigegebenen Quellen keine belastbare Antwort.“ Diese Grenze ist ein Qualitätsmerkmal, kein Fehler.
Nächste Schritte
Drei Fragen klären die Machbarkeit schneller als jede Tool-Demo:
- Datenlage: Welche Quelle ist aktuell, freigegeben und klar verantwortet – und welcher Fragetyp soll zuerst beantwortet werden?
- Berechtigungen: Gibt es SSO, Gruppen oder Rollen, die der Chatbot pro Nutzer übernehmen muss?
- Risiko: Wie nah kommen Antworten an Entscheidungen mit rechtlicher, finanzieller oder HR-Wirkung?
Wenn diese Punkte unklar sind, ist der erste Schritt kein Chatbot-Bau, sondern ein Daten- und Rechtecheck. Wir starten je nach Reifegrad mit einer KI-Strategie oder direkt mit einem begrenzten RAG-Piloten. Schildern Sie uns Zielgruppe, Datenquellen und den kritischsten Frage-Antwort-Prozess – dann buchen Sie ein Erstgespräch.