
KI schreibt heute Code in Sekunden – und genau das ist die Versuchung wie das Risiko. Der Veracode GenAI Code Security Report 2025 hat über 100 Modelle bei mehr als 80 Coding-Aufgaben getestet: In 45 % der erzeugten Code-Samples steckte mindestens eine Schwachstelle aus den OWASP Top 10. Neuere oder größere Modelle schnitten dabei nicht besser ab – das Problem ist strukturell, nicht eine Frage des nächsten Releases.
Das ist kein Argument gegen KI. Es ist ein Argument gegen unkontrollierte KI. Wer KI in der Softwareentwicklung naiv einsetzt, importiert neue Risikoklassen direkt in die Produktion. Wer sie diszipliniert einsetzt, gewinnt Tempo, ohne die Kontrolle abzugeben. Dieser Unterschied – Disziplin – ist die eigentliche Leistung einer Agentur.
Die neuen Risikoklassen – mit Zahlen
KI verschiebt nicht nur das Tempo, sie verschiebt das Risikoprofil. Drei Effekte sind belegbar und für jeden relevant, der KI-generierten Code in Produktion bringt: unsicherer Code, halluzinierte Abhängigkeiten und steigender Code-Churn. Dazu kommt eine vierte, vertragliche Klasse: Daten- und IP-Abfluss.
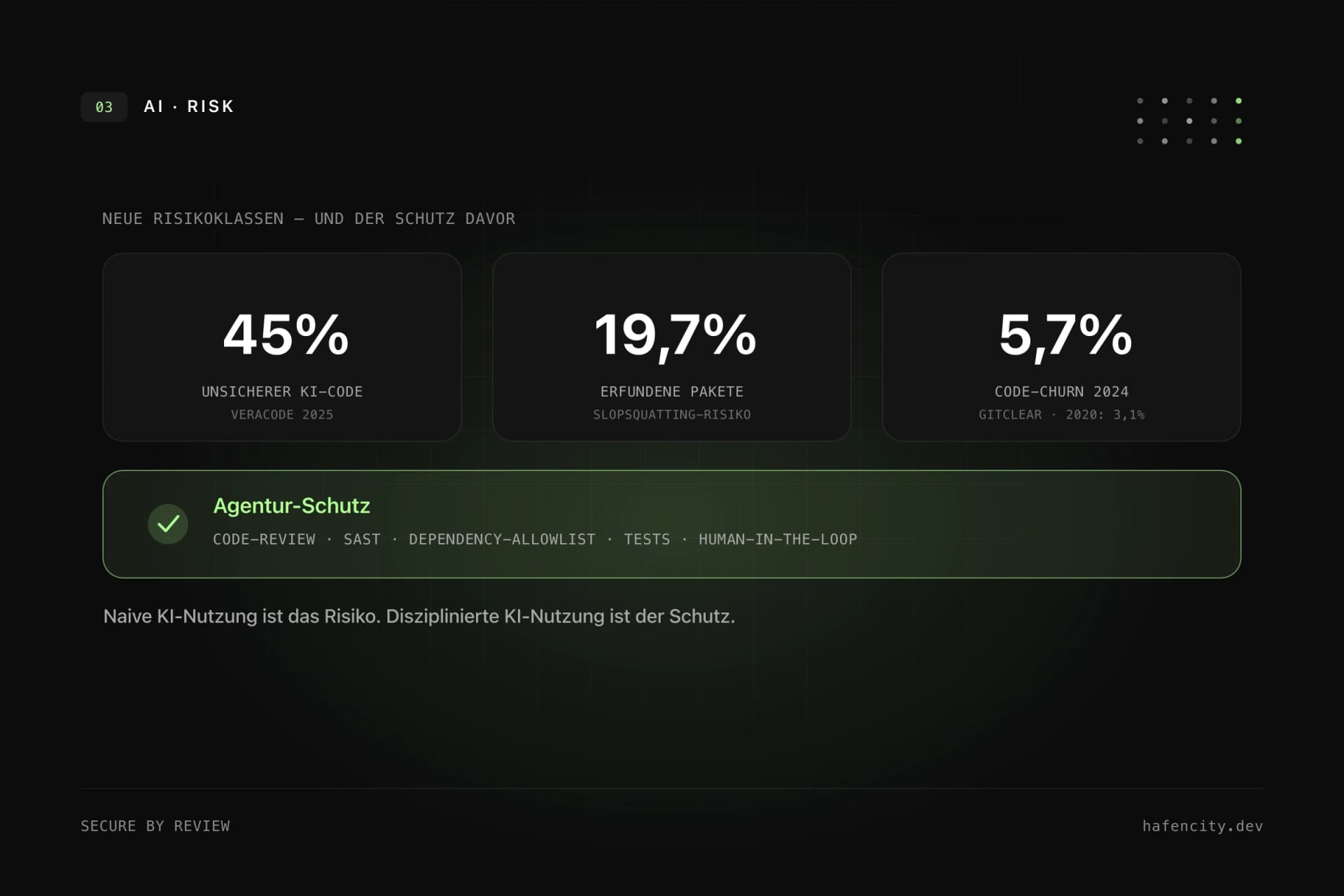
Der unsichere Code ist der direkteste Effekt: 45 % Schwachstellenquote bedeutet nicht, dass jede zweite Zeile kaputt ist, sondern dass bei knapp der Hälfte der gelösten Aufgaben eine ausnutzbare Lücke übrig blieb. Halluzinierte Pakete sind subtiler: Modelle erfinden Bibliotheksnamen, die plausibel klingen, aber nicht existieren. Laut einer in BleepingComputer zusammengefassten Studie referenzierten rund 19,7 % der Samples ein solches Paket – und weil sich die Namen wiederholen, kann ein Angreifer sie registrieren und Schadcode unterschieben („Slopsquatting"). Der Code-Churn schließlich ist das leiseste Signal: Laut GitClear wird mehr Code kurz nach dem Schreiben wieder verworfen und häufiger kopiert statt sauber refaktoriert – ein Frühindikator für Wartungslast.
| Risikoklasse | Was passiert | Befund | Gegenmittel |
|---|---|---|---|
| Unsicherer Code | OWASP-Schwachstellen im Output | 45 % der Samples (Veracode 2025) | Review + SAST/Security-Scan |
| Halluzinierte Pakete | erfundene Abhängigkeiten | 19,7 % der Samples (Slopsquatting) | Dependency-Allowlist + Pinning |
| Code-Churn / Tech-Debt | kopiert statt refaktoriert | 3,1 % → 5,7 % (GitClear) | Tests, CI-Gates, Architektur |
| Daten- / IP-Abfluss | Code an externe Modelle | DSGVO & EU AI Act | klare Datengrenzen |
Warum naive KI-Nutzung in der Produktion zubeißt
Der gefährlichste Moment ist nicht der Prototyp, sondern der Tag, an dem ungeprüfter KI-Code live geht. KI ist exzellent darin, etwas zu erzeugen, das fast richtig ist – und „fast richtig" ist in der Produktion die teuerste Kategorie. Im Stack Overflow Developer Survey 2025 nennen 66 % der Entwickler genau das als größte Frustration; für rund 45 % dauert das Debuggen von KI-Code länger als es selbst zu schreiben. Das Tempo am Anfang täuscht über die Kosten am Ende hinweg.
Diese Dynamik ist auch auf Team-Ebene messbar. Der DORA-Report 2025 bestätigt einerseits, dass KI die Produktivität verstärkt – mehr erledigte Aufgaben, mehr gemergte Pull Requests. Andererseits zeigt er eine negative Beziehung zwischen KI-Adoption und Lieferstabilität, solange kein starkes Fundament aus automatisierten Tests, Versionskontrolle und schnellem Feedback existiert. KI verstärkt, was schon da ist: Wo Disziplin fehlt, verstärkt sie die Instabilität. Wo Disziplin existiert, verstärkt sie die Qualität. Genau diese Logik haben wir in Risiken in KI-Softwareprojekten und Governance ausführlicher beschrieben.
Die Absicherung: der Stack, den eine Agentur dazwischenschaltet
Jede einzelne Risikoklasse hat ein etabliertes Gegenmittel – die Kunst ist, sie als verbindlichen Layer zu betreiben, nicht als guten Vorsatz. Eine Agentur, die KI ernst nimmt, behandelt KI-Output wie Code eines neuen Teammitglieds: nützlich, aber nie ungeprüft im Merge. Darüber liegt ein Governance-Layer, der eine einfache Regel durchsetzt – KI ist Werkzeug, der Mensch entscheidet und haftet.
Konkret sind das sechs Maßnahmen, die ineinandergreifen:
- Code-Review im Vier-Augen-Prinzip: Keine KI-generierte Zeile geht ohne menschliche Freigabe in den Hauptzweig. Das fängt sowohl die 45-%-Schwachstellen als auch subtile Logikfehler ab.
- SAST & Security-Scan im CI: Automatische OWASP-Checks bei jedem Merge, damit Sicherheit nicht von Tagesform abhängt.
- Dependency-Allowlist & Pinning: Nur freigegebene, versionsfixierte Pakete – die direkte Antwort auf Slopsquatting. Snyk empfiehlt hier verifizierte Quellen und Lockfiles als Standard.
- Tests & CI-Gates: Automatisierte Tests sind das Fundament, das laut DORA über Stabilität entscheidet – sie verwandeln Tempo in verlässliche Releases.
- Daten- & Secret-Grenzen: Definierte Tool-Liste, kein proprietärer Code an fremde Modelle, keine Secrets in Prompts.
- Lizenz- & IP-Prüfung: Herkunft und Lizenzlage des Outputs werden geklärt, bevor er ausgeliefert wird.
Wie diese Praktiken in einem strukturierten Review zusammenkommen, zeigt unser Software-Audit & Code-Review.
Daten, IP und der EU AI Act
Sobald proprietärer Code ein externes Modell verlässt, wird aus einem Technik- ein Rechtsthema. Zwei Fragen sind zu klären: Was passiert mit den Daten, die du an das Modell sendest – und wem gehört der Output? Praktisch heißt das, eine klare Trennlinie zu ziehen: Welche Repositories dürfen KI-Tools sehen, welche nicht; ob der Anbieter auf deinen Daten trainiert; und ob Secrets oder Kundendaten überhaupt in die Nähe eines Prompts kommen.
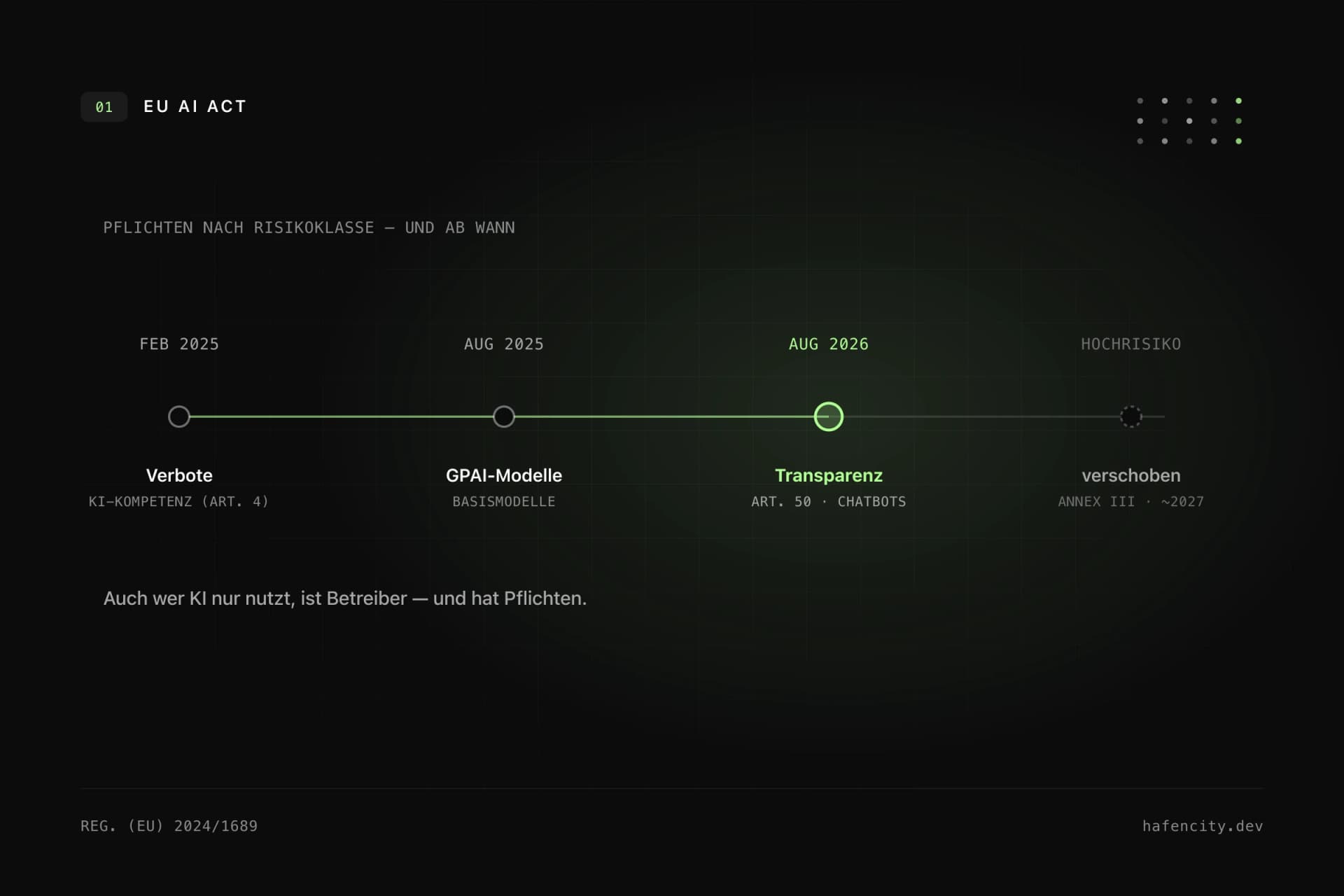
Dazu kommt der regulatorische Rahmen. Der EU AI Act ist seit dem 1. August 2024 in Kraft und wird gestaffelt wirksam; je nach Einsatz entstehen Dokumentations- und Transparenzpflichten. Für die Codegenerierung selbst bedeutet das selten dramatische Hürden, aber eine klare Erwartung: nachvollziehbare Prozesse, dokumentierte Tool-Nutzung, saubere Datengrenzen. Eine Agentur, die KI professionell nutzt, hat diese Grenzen vertraglich und technisch ohnehin gezogen.
Woran du eine disziplinierte KI-Agentur erkennst
Der Unterschied zwischen einem Profi und einem „Vibe-Coder" zeigt sich nicht im Tempo, sondern in der Frage nach der Absicherung. Frag konkret nach – die Antworten sind ein zuverlässiger Filter:
- Geht jede KI-generierte Zeile durch Review, oder nur „die wichtigen"?
- Laufen Security-Scans automatisch im CI, oder gelegentlich von Hand?
- Gibt es eine Dependency-Allowlist und Lockfiles gegen halluzinierte Pakete?
- Sind Tests ein verbindliches Gate, das Merges blockiert?
- Existieren dokumentierte Datengrenzen – welcher Code welches Tool sehen darf?
Wer hier mit „natürlich, so arbeiten wir" und konkreten Beispielen antwortet, nutzt KI als das, was sie ist: ein Beschleuniger im Rahmen solider Technik. Wer ausweicht oder nur über Geschwindigkeit spricht, verlagert das Risiko auf dein Produkt. Mehr dazu, wie sich KI sauber in den Entwicklungsalltag einbettet, steht in KI-Coding mit Codex und Claude sowie in unseren Schwester-Beiträgen Wie eine Agentur mit KI schneller liefert und Ersetzt KI die Software-Agentur?.
Nächste Schritte
Drei Fragen zeigen schnell, ob dein KI-Code abgesichert ist:
- Review: Geht jede KI-generierte Zeile durch ein menschliches Code-Review, bevor sie live geht?
- Supply Chain: Schützt eine Dependency-Allowlist mit Pinning vor halluzinierten oder untergeschobenen Paketen?
- Datengrenzen: Ist klar geregelt, welcher Code welches KI-Tool sehen darf – und was mit deinen Daten passiert?
Wenn eine dieser Fragen unbeantwortet bleibt, lohnt ein Blick von außen. Wir setzen KI in Projekten produktiv ein – mit genau dieser Absicherung. Sieh dir unsere KI-Integration und Entwicklung an oder buche direkt ein Erstgespräch.