
Many companies want "ChatGPT with company data". Usually, they do not mean a general chatbot, but a system that searches internal documents, knowledge bases, product information, policies or support data and creates traceable answers from them. Technically, this is often built with RAG: Retrieval-Augmented Generation.
Short answer: An AI chatbot with company knowledge connects approved data sources with search, permissions and a language model. A first RAG prototype often costs 20,000 to 60,000 EUR. A production enterprise chatbot with role model, SSO, several integrations, monitoring, evaluation, privacy concept and operations often ranges from 60,000 to 180,000 EUR or more. A simple website FAQ bot can be significantly cheaper.
The difference between a demo and a production system is large. A demo answers questions from a few PDFs. A production enterprise chatbot must know which data a user is allowed to see, when it is uncertain, how sources are cited, which answers are logged and how quality is measured continuously.
What is an AI chatbot with company knowledge?
An AI chatbot with company knowledge does not answer only from general model knowledge. It uses approved company sources as context. These can include documents, wikis, tickets, CRM data, product data sheets, manuals, website content or internal policies.
Typical use cases:
- internal knowledge assistant for policies, processes and onboarding
- support chatbot with access to help center, tickets and product documentation
- sales enablement for product information, pricing logic and proposal modules
- technical assistant for manuals, specifications and maintenance data
- HR assistant for internal rules, benefits and onboarding documents
- customer portal assistant for contracts, invoices, status and documents
- project assistant for meeting notes, decisions, specifications and open points
Important: The chatbot should not "know everything". It should use clearly defined sources, know its limits and avoid inventing answers when evidence is missing.
Website FAQ bot or enterprise RAG chatbot?
Many misunderstandings happen because very different systems are all called "AI chatbot". For a website FAQ, a standard tool is often enough. For company knowledge with permissions, SSO, sensitive data and multiple systems, a different architecture is required.
| Type | Suitable for | Limits |
|---|---|---|
| Website FAQ bot | public questions, help center, simple lead qualification | limited permissions, limited integrations, usually simple sources |
| Internal knowledge bot | policies, onboarding, process knowledge, product documentation | requires data maintenance, roles and clear source ownership |
| Support RAG bot | tickets, product documentation, issue database, answer drafts | requires quality assurance and human approval for critical cases |
| Customer portal assistant | customer-specific documents, status, contracts, invoices | requires strict tenant separation and backend permissions |
| Agentic workflow | chatbot plus actions in CRM, ticketing, email or ERP | requires tool limits, audit logs, approvals and monitoring |
The biggest mistake is to start with a simple demo chatbot and later unleash it on sensitive company data without control. It is better to define data sources, permissions and pilot goals properly from the beginning.
When a RAG chatbot makes sense and when it does not
RAG is useful when a lot of information already exists in documents or systems, but is hard to find or understand. The approach is especially strong when answers need to reference sources.
Good use cases:
- support teams search product and issue databases faster
- new employees find policies and process knowledge
- sales teams get consistent answers to product questions
- customers receive self-service answers from approved documents
- project teams search specifications, meeting notes and decisions
- departments review long documents faster for relevant passages
Bad use cases:
- the data base is outdated, contradictory or not approved
- there are no clear data owners
- answers would have legal, medical or financial impact without human review
- user permissions are unclear and sensitive data is mixed together
- the chatbot should make decisions before answer quality is measurable
- the company actually has a process or data quality problem but calls it "AI"
An AI chatbot is not a replacement for information architecture. If nobody knows which source is authoritative, a model cannot magically create that governance.
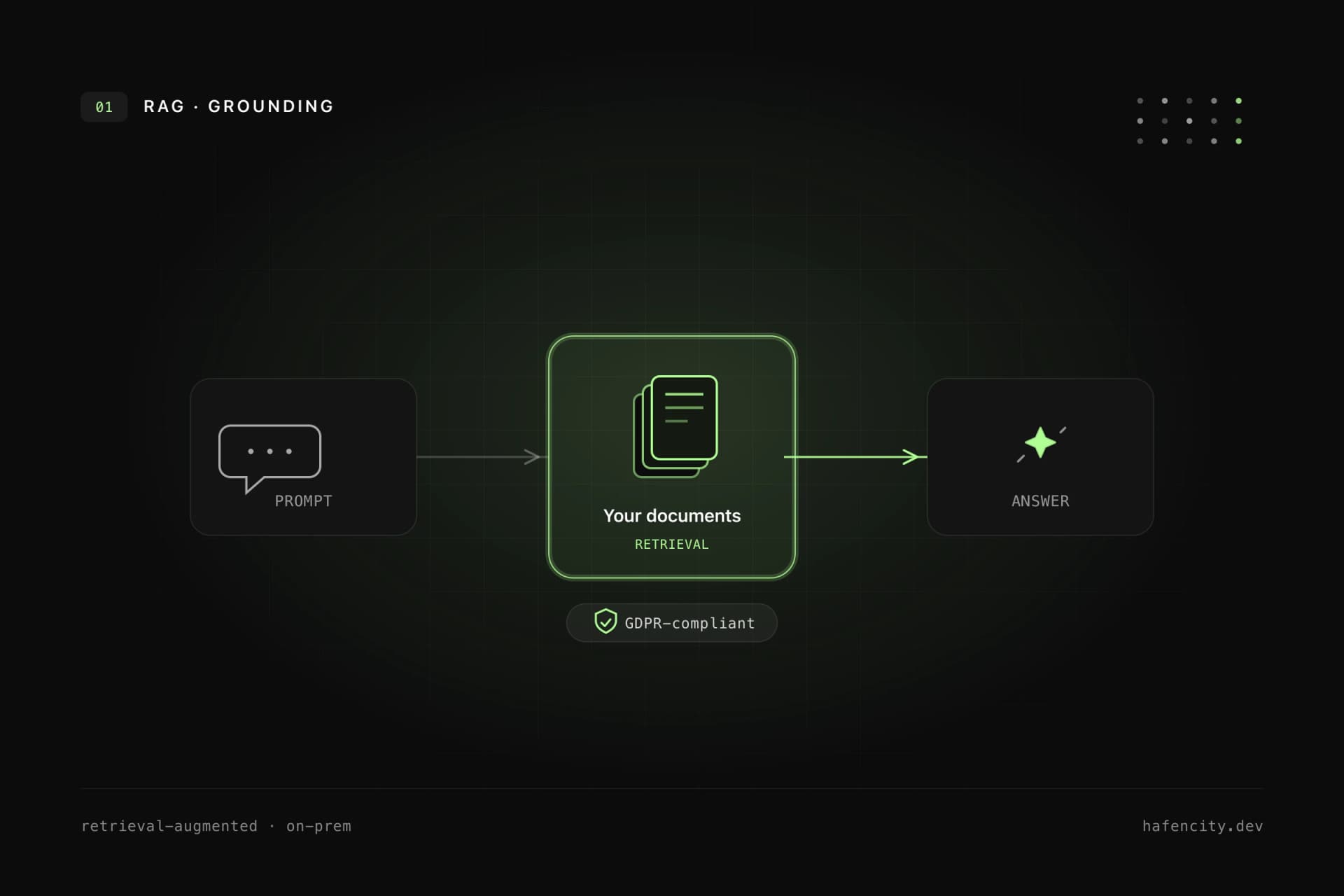
How RAG works technically
RAG stands for Retrieval-Augmented Generation. The system first searches for relevant information and then lets the language model answer based on that context.
A typical flow:
- Sources are connected: for example Confluence, SharePoint, Google Drive, Notion, website, CRM or PDFs.
- Content is cleaned, split into segments and enriched with metadata.
- Text segments are converted into embeddings and stored in a search index or vector database.
- When a user asks a question, the system searches for matching segments.
- Permissions filter which results the user is allowed to see.
- The language model creates an answer with source references.
- Feedback, logs and evaluation show whether the answer was useful.
The critical point sits between steps 4 and 6. Without permission checks, the chatbot can expose confidential information. Without good retrieval quality, the model receives the wrong context. Without evaluation, nobody notices when answer quality gets worse.
Data sources and prioritization
The data sources determine quality more than the model. Common sources include:
- knowledge bases: Confluence, Notion, SharePoint, Google Drive
- documents: PDFs, Word files, presentations, product sheets, contracts
- support: Zendesk, Intercom, Jira Service Management, Freshdesk
- CRM and sales: HubSpot, Salesforce, Pipedrive, internal databases
- product data: PIM, ERP, CMS, technical documentation
- website and help center: public content, FAQ, documentation
- internal systems: project management, tickets, wikis, databases
Not every source should be connected first. Good first sources are current, maintained, clearly owned and useful for a specific question type. Bad first sources are old shared drives, duplicated PDF collections, unclear exports or documents with mixed permissions.
For a pilot, one strong source is often better than ten weak ones. Production systems need synchronization, change tracking, error handling, duplicate detection and clear data ownership.
Permissions: the most important enterprise topic
An enterprise chatbot must not only provide good answers. It must provide the right answers to the right people. This is often the biggest technical and organizational challenge.
Examples:
- HR documents must not be visible to all employees.
- Customer data may only be read by the responsible team.
- Financial data does not belong in general search results.
- Drafts, outdated versions or confidential contracts must not appear unchecked in answers.
- External customers may only see their own documents.
Permissions must be considered during retrieval, not only in the interface. If an unauthorized text segment reaches the model context, the damage has already happened. A clean system connects user identity, roles, groups, document metadata and backend checks.
Security: prompt injection, tool limits and output validation
LLM applications have their own security risks. OWASP's LLM Top 10 names prompt injection, insecure output handling, supply-chain vulnerabilities and excessive agency as relevant risk areas. For a company chatbot, this means security is not limited to server hardening.
Practical safeguards include:
- separate system instructions, retrieved content and user input clearly
- never treat retrieved documents as trusted instructions
- limit which tools the chatbot may call
- validate tool parameters before execution
- use allowlists for actions and systems
- require human approval for risky actions
- log retrieval, prompts, tool calls and answers in a privacy-aware way
- sanitize generated output before it is used in downstream systems
- test with malicious documents and prompt injection attempts
The chatbot should not be able to execute arbitrary actions because a document or user message instructs it to do so. RAG answers and agentic tool calls must be treated as separate risk levels.
Privacy, logging and the EU AI Act
AI chatbots for companies almost always touch personal or confidential data. This does not replace legal advice, but these technical questions should be clarified early:
- Which data sources contain personal data?
- Which content may be sent to model providers?
- Where are prompts, answers, logs and embeddings stored?
- How long are interactions retained?
- Who can view chat histories and feedback?
- Can users request access, correction or deletion?
- How are sources, permissions and answer quality documented?
The EU AI Act is also relevant. The European Commission describes the AI Act as a risk-based framework. It entered into force on 1 August 2024. Prohibited-practices and AI-literacy obligations have applied since 2 February 2025, GPAI and governance obligations since 2 August 2025, and many rules become applicable from 2 August 2026. The Commission also describes transparency obligations for chatbots: people should be informed when they interact with a machine. According to the Commission, transparency rules apply from August 2026.
In practice, this means an internal knowledge chatbot needs clear notices, responsibilities, purpose definition, data flows, risk assessment and control mechanisms. The closer the chatbot gets to decisions with legal, financial, HR or health impact, the more tightly the system must be limited.
Cost and timeline: pilot vs. production
An AI chatbot should be built in stages. The first pilot answers whether data quality, retrieval and value are viable. The production version answers whether permissions, quality, operations and integration are reliable.
| Phase | Duration | Typical effort |
|---|---|---|
| Discovery and data check | 1 to 2 weeks | use case, sources, privacy, risks, success metrics |
| RAG prototype | 2 to 5 weeks | one data source, simple interface, source-based answers |
| Pilot | 4 to 8 weeks | user group, feedback, evaluation, first permission checks |
| Production system | 8 to 20 weeks | roles, SSO, integrations, monitoring, admin, operations |
| Ongoing development | continuous | new sources, quality assurance, cost control, governance |
Typical cost ranges:
| Project type | Realistic range |
|---|---|
| Data and use-case check | 5,000 to 15,000 EUR |
| RAG prototype | 20,000 to 60,000 EUR |
| Pilot with real users | 40,000 to 100,000 EUR |
| Production enterprise chatbot | 60,000 to 180,000 EUR and more |
Additional running costs include model usage, embedding generation, vector database, hosting, monitoring, maintenance, data synchronization, evaluation and support.
Pilot metrics: how to decide whether it works
A pilot should not end with "people liked the demo". It should produce measurable evidence.
Useful metrics:
- answer accuracy on a fixed evaluation set
- source coverage: how often the correct source is found
- refusal quality: whether the bot declines when evidence is missing
- time saved per question or ticket
- reduction in repeated support questions
- user satisfaction by role
- number of escalations to humans
- cost per answer
- latency and uptime
- incidents related to permissions or wrong sources
These metrics help distinguish a promising demo from a system that should actually enter production.
How to reduce hallucinations
Hallucinations cannot be eliminated completely, but they can be reduced and measured. The key is not just a better prompt, but a quality system.
Important measures:
- clear sources that are current and approved
- retrieval tests with known questions and expected sources
- answer rules: answer only when enough context exists
- source references directly next to the answer
- refusal behavior when uncertain
- feedback buttons and error categories
- regular evaluation sets
- monitoring for cost, latency, retrieval quality and error rates
- escalation to humans for critical questions
A production chatbot should be able to say: "I cannot find a reliable answer in the approved sources." That boundary is a quality feature, not a bug.
SaaS tool, custom chatbot or hybrid approach?
Many SaaS tools provide quick chatbots for help centers, website FAQ or internal documents. That is useful when data sources are standardized, permissions are simple and deep integrations are not needed.
Custom development is worthwhile when:
- several internal systems need to be connected
- permissions apply per user, customer or document
- sensitive data is processed
- answers need to include business logic
- the chatbot is embedded into a customer portal, CRM or internal tool
- audit logs, evaluation and monitoring should stay under your control
A hybrid approach is often best: SaaS for standard functionality, a custom backend layer for permissions, integrations, data preparation and quality assurance.
AI data readiness check
Before a RAG project, a company should answer these questions:
- Which user group has the highest value?
- Which three question types should the chatbot answer first?
- Which sources are current, approved and maintained by clear owners?
- Which sources contain personal or confidential data?
- Which permissions currently apply in the source systems?
- Is there SSO, groups or roles that can be reused?
- Which answers may only be suggestions?
- Which sources must be cited?
- How is quality measured?
- Who is the business owner after launch?
- Which cost limits apply to model usage and infrastructure?
If these questions are not answered, the first step should not be chatbot development, but a data and permissions check.
How hafencity.dev builds AI chatbots
We build AI chatbots as AI integrations, not as isolated demos. That includes data check, RAG architecture, backend, permission model, evaluation, monitoring and integration into existing workflows. Depending on maturity, we start with an AI strategy, a limited RAG pilot or a production-oriented integration.
In a first conversation, it is usually possible to clarify whether a RAG chatbot is realistic for your data situation, which sources are suitable first and which risks must be checked before a pilot.
If you want to assess this, you can request an AI chatbot project. A complete specification is not required. A short description of target users, data sources, permissions and the most critical question-answer workflow is enough.
FAQ
What does an AI chatbot with company knowledge cost?
A simple RAG prototype often costs 20,000 to 60,000 EUR. A production enterprise chatbot with permissions, SSO, several data sources, evaluation and monitoring often ranges from 60,000 to 180,000 EUR or more.
Can ChatGPT be connected to company data?
Yes, but not by simply uploading arbitrary documents. Production use requires data preparation, permissions, privacy review, logging, source references and clear rules for which data may go to which provider.
Can a RAG chatbot be GDPR-compliant?
Yes, if data flows, legal basis, processing agreements, hosting, retention periods, deletion concept and access controls are planned properly. It is especially important not to store personal data unnecessarily in prompts, logs or embeddings.
How do you prevent wrong answers?
Through good sources, retrieval tests, source references, answer rules, refusal behavior, feedback and regular evaluation. Errors cannot be eliminated completely, so critical processes need human control.
Which data sources are suitable?
Good first sources are current, maintained and clearly owned content: help centers, product documentation, internal process manuals, approved PDFs or knowledge bases. Poor sources are old, contradictory or unauthorized document collections.
Sources and further reading
- Our service: AI Integration
- Our service: AI Agents
- AI Agency Hamburg: Starting AI Projects
- AI Use Cases for Companies
- AI Agents in Companies
- When an AI Prototype Looks Finished but Is Not Production-Ready
- European Commission: AI Act
- OWASP Top 10 for LLM Applications
- Google Search Central: Structured data