
Enterprise AI is no longer a pilot topic in 2026: according to Bitkom's 2026 AI study, 41 percent of companies with 20 or more employees actively use AI, and another 48 percent are planning or discussing it. The most common request behind this is "ChatGPT with our own data". Usually it does not mean a general chatbot, but a system that searches internal documents, wikis and support data and creates traceable answers from them. The technical approach is Retrieval-Augmented Generation (RAG).
The gap between a demo and a production system is large. A demo answers questions from a few PDFs. A production enterprise chatbot must know which data a user may see, when it is uncertain, how sources are cited and how quality is measured continuously.
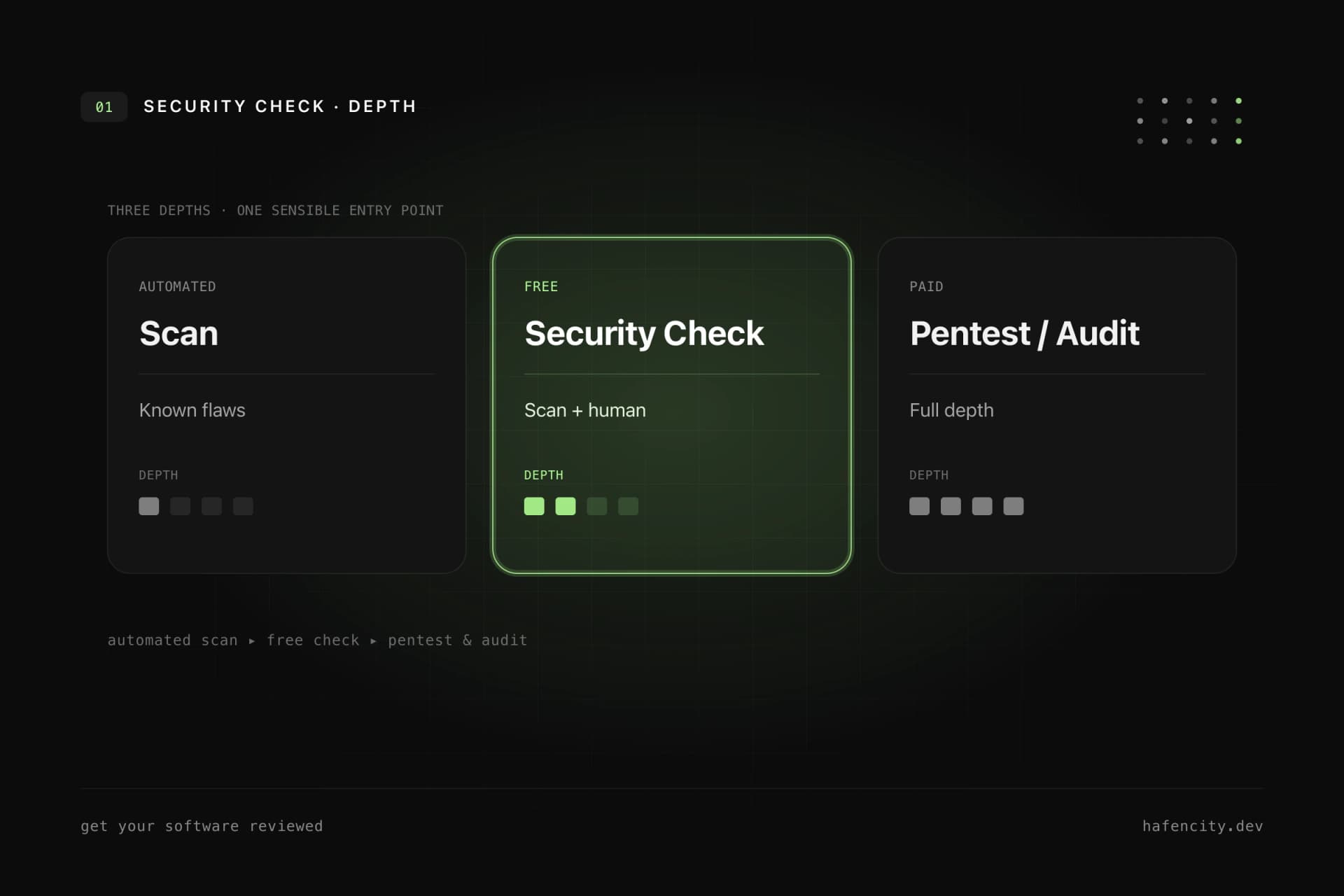
Demo or production: the expensive difference
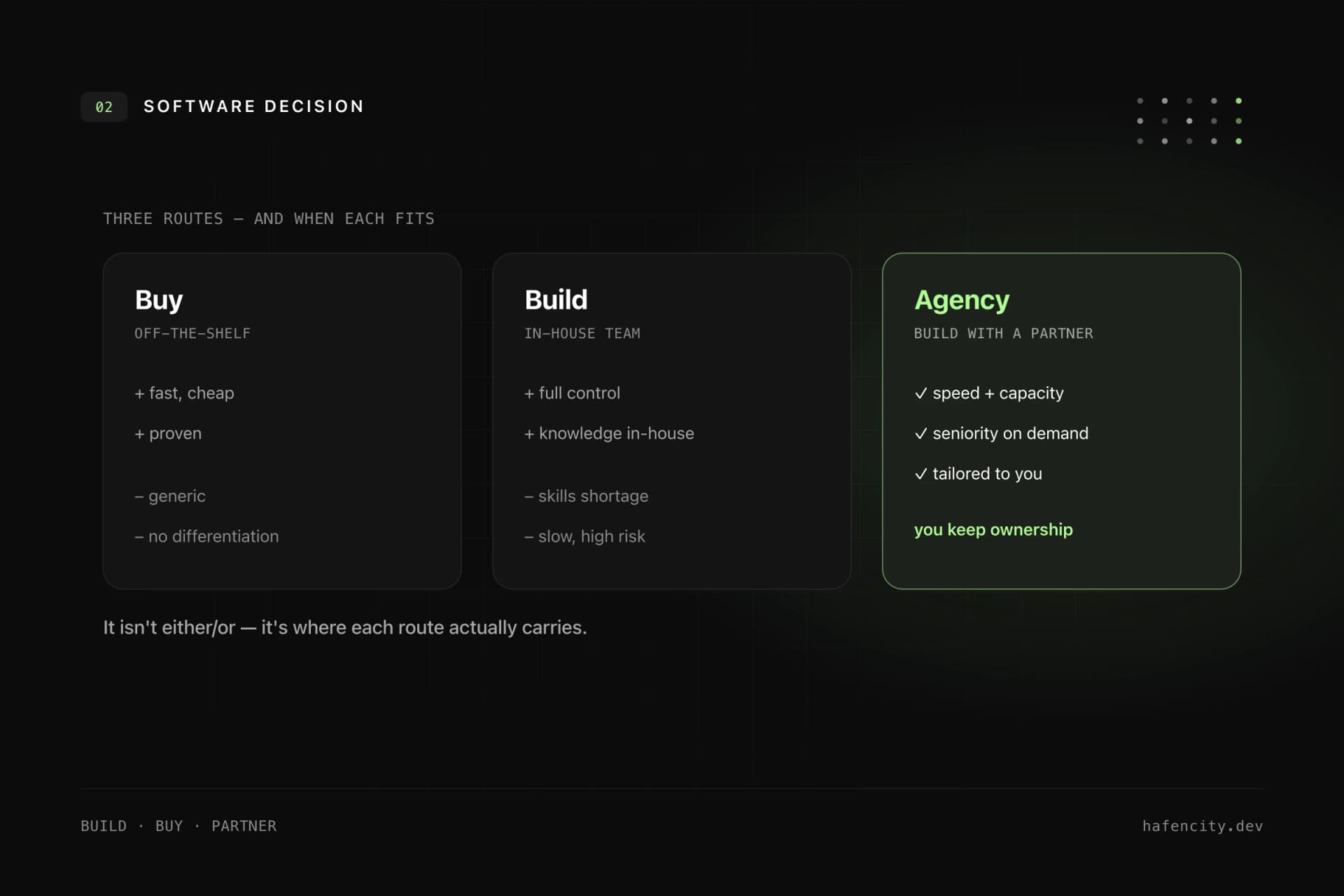
Very different systems are all called "AI chatbot" — and that is where most wrong decisions begin. For a public website FAQ, a standard tool is often enough. For company knowledge with permissions, SSO, sensitive data and multiple systems, a different architecture is required. The most common expensive mistake is to start with a simple demo bot and later unleash it on sensitive data without control.
| Type | Suitable for | Limits |
|---|---|---|
| Website FAQ bot | public questions, help center, simple lead qualification | limited permissions, simple sources |
| Internal knowledge bot | policies, onboarding, process knowledge, product docs | requires data maintenance, roles, source ownership |
| Support RAG bot | tickets, product docs, issue database, answer drafts | requires quality assurance and human approval |
| Customer portal assistant | customer-specific documents, status, contracts | requires strict tenant separation |
| Agentic workflow | chatbot plus actions in CRM, ticketing, ERP | requires tool limits, audit logs, approvals |
The honest question before you start is not "which model?" but: which data sources, which permissions, which concrete question-answer process?
How permission-aware RAG works
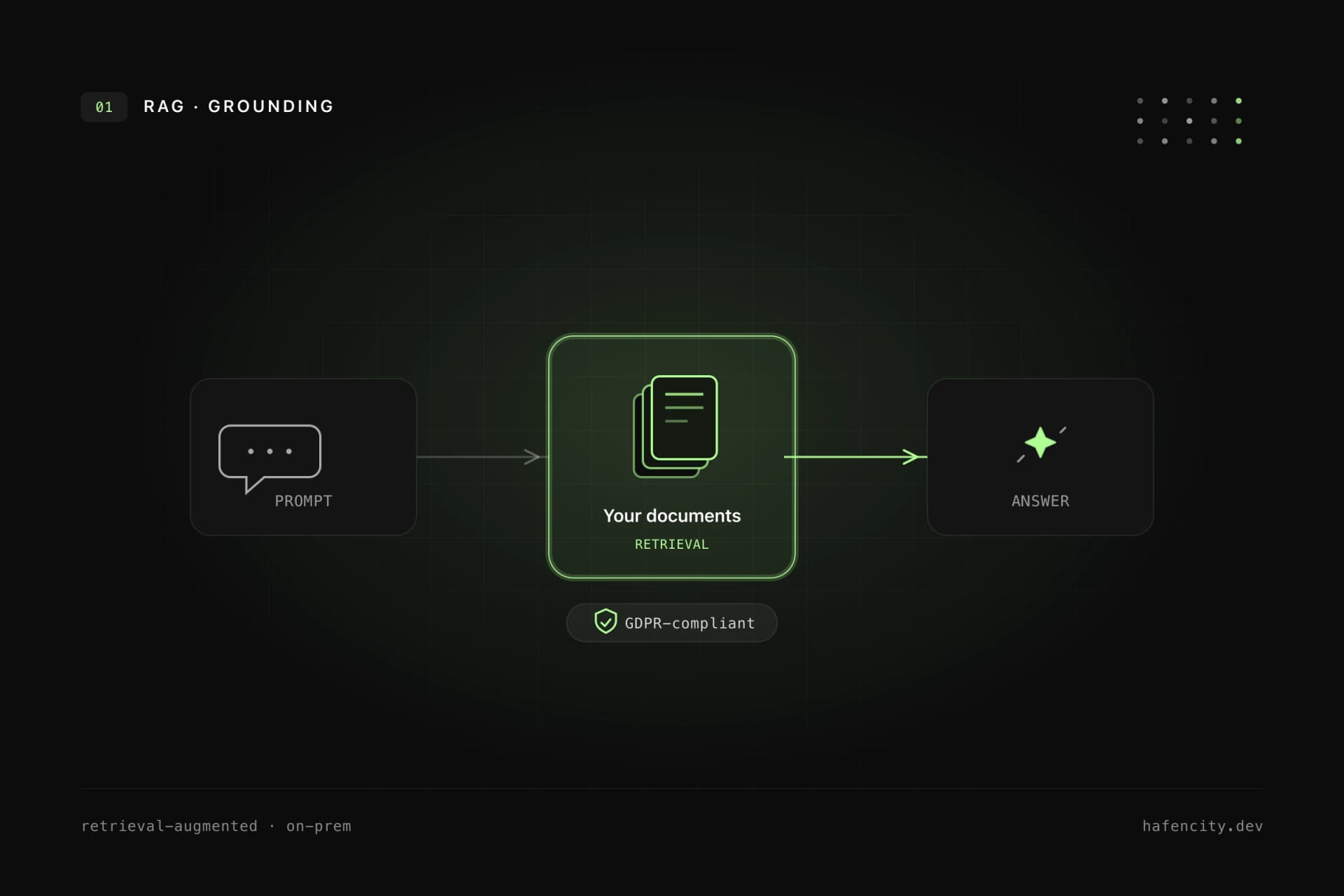
In an enterprise, the most important architecture point is not the prompt, but the question of which data is even allowed into the model context. RAG first searches for relevant information and then lets the language model answer based on that context. The critical step sits between search and answer: the permission check.
A permission-aware system checks, before every answer, who the user is, which role they hold, and which documents, tickets or records they may see — including rights from SharePoint, Google Drive, CRM or your own backend. This check belongs in the backend and must apply to every request, not only at login. For customer portals, HR, contract or financial data, this is the difference between demo and production: once an unauthorised segment reaches the model, access control has already failed. How we build such systems is shown in our AI integration.
Data sources: where the pilot starts
The data sources determine quality more than the model. Not every source should be connected first. Good first sources are current, reviewed, clearly owned and not very sensitive. Bad first sources are huge folder structures with old, contradictory or unauthorised documents.
| Data source | Pilot suitability | Why |
|---|---|---|
| maintained help center | high | clear content, frequent questions, good source references |
| product documentation | high | easy to structure, high value for support and sales |
| internal process manuals | medium to high | useful when current and responsibly maintained |
| SharePoint/drive with legacy files | low to medium | needs cleanup, metadata, permission checks |
| CRM and ticket data | medium | useful, but personal and permission-dependent |
| contracts and HR documents | cautious | highly sensitive, clear roles and approvals required |
A good pilot does not start with "all data" but with one valuable, controllable source and a clear question type. Production then adds synchronization, change tracking, duplicate detection and clear data owners. More on this in getting started with AI use cases.
Privacy, the EU AI Act and security
Enterprise chatbots almost always touch personal or confidential data — so governance is part of the architecture, not an appendix. A few technical questions should have clear answers early: which sources contain personal data? Which content may go to model providers? Where do prompts, answers, logs and embeddings live, for how long, and who can view them?
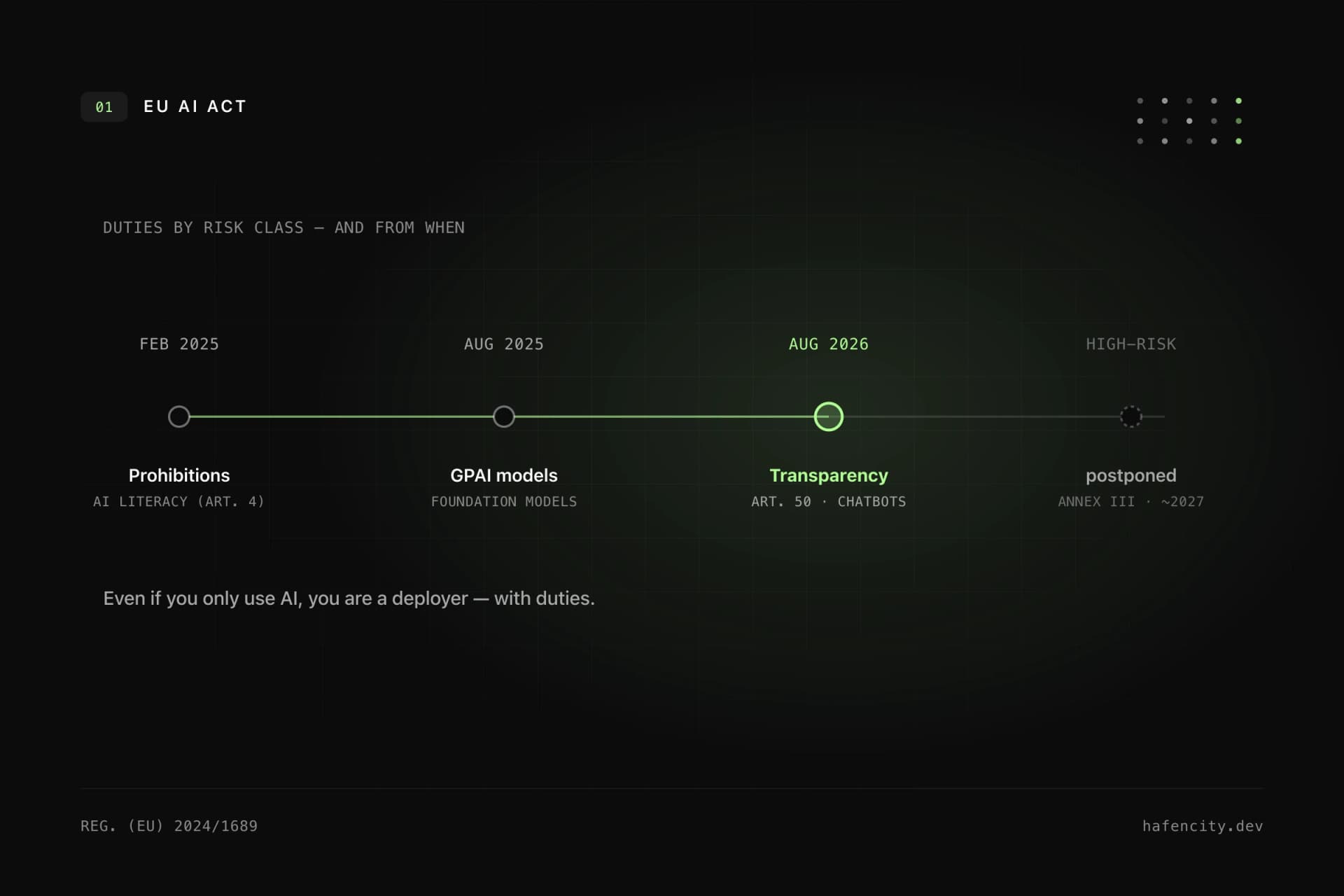
The EU AI Act has been in force since 1 August 2024 and applies in stages. For chatbots, Article 50 matters most: the transparency obligations apply from 2 August 2026 — users must clearly recognise that they are talking to an AI system. With the Digital Omnibus proposed in late 2025, lawmakers agreed in May 2026 to postpone the obligations for high-risk Annex III systems from August 2026 to 2 December 2027. Most internal knowledge chatbots are not high-risk systems, but they still need transparency, purpose limitation, risk assessment and documentation.
Security is a separate concern. As soon as a chatbot reads external content or triggers actions, a document or user message can carry hidden instructions. In the OWASP Top 10 for LLM Applications (2025), prompt injection ranks first, with newly weighted weaknesses in vector and embedding systems relevant for RAG. Practical safeguards: separate the system instruction, retrieved content and user input; validate tool calls server-side; keep secrets out of prompts and logs; and require human approval for irreversible actions. A RAG chatbot becomes safer when it is allowed to do less — more in risks in AI software projects.
Cost and roadmap: pilot before production
An AI chatbot should be built in stages — the pilot answers whether data quality and value are viable before you invest in roles, SSO and operations. The ranges below are our typical project sizes, not list prices; the actual number depends on sources, integrations and compliance depth.
| Project type | Realistic range | What's included |
|---|---|---|
| Data and use-case check | 5,000–15,000 EUR | use case, sources, privacy, success metrics |
| RAG prototype | 20,000–60,000 EUR | one source, simple interface, source-based answers |
| Pilot with real users | 40,000–100,000 EUR | user group, evaluation, first permission checks |
| Production enterprise chatbot | 60,000–180,000 EUR and more | roles, SSO, integrations, monitoring, operations |
On top come running costs, often smaller than expected: embeddings cost roughly $0.02 per million tokens with OpenAI's text-embedding-3-small; the ongoing drivers are model calls per answer, the vector database, hosting and monitoring. More important than the entry price is whether answer quality stays measurable: maintained sources, retrieval tests, source references, refusal behavior when uncertain and an evaluation set. A production chatbot should be able to say: "I cannot find a reliable answer in the approved sources." That boundary is a quality feature, not a bug.
Next steps
Three questions settle feasibility faster than any tool demo:
- Data situation: which source is current, approved and clearly owned — and which question type should be answered first?
- Permissions: is there SSO, groups or roles the chatbot must carry over per user?
- Risk: how close do answers get to decisions with legal, financial or HR impact?
If these points are unclear, the first step is not chatbot development but a data and permissions check. Depending on maturity, we start with an AI strategy or directly with a limited RAG pilot. Describe your target users, data sources and most critical question-answer process — then book an intro call.