
An AI prototype can look like a finished product in just a few days: a clean interface, a working demo, impressive first screens. That is the strength of modern AI tools — and that is the trap. Since Andrej Karpathy coined the term "vibe coding" in early 2025 (Collins Word of the Year 2025), generating working interfaces by prompt has become routine. In the Stack Overflow Developer Survey 2025, 84% of developers say they use or plan to use AI tools.
In our work as a software agency, we increasingly see the next phase: companies arrive with a self-built AI prototype and want to turn it into a reliable product. At first glance, a lot looks finished. But once we inspect code, data model, authentication, failure modes and operations, a different picture appears: the surface has come far, the product has not. That is not a criticism — it only becomes risky when a demo state is mistaken for real software.
Why AI prototypes feel so convincing
AI tools are excellent at creating visible product elements quickly — and that is exactly what deceives. Landing pages, dashboards, forms, tables, first app screens, sample workflows: within days a team can see whether an idea works visually, collect user feedback and show something to investors. For early product phases, that is a genuine win.
The problem: most critical properties of production software are invisible in a demo. A demo has to impress once. Production has to work reliably, securely and under real load every single day. That the gap is real shows in how fast this spread — per Wikipedia, a quarter of Y Combinator's early-2025 startup cohort had codebases that were roughly 95% AI-generated. Visible progress and durable substance are simply not the same thing.
The AI-code reality in numbers
The psychological effect is dangerous: what looks professional feels almost finished — the data says otherwise. Three current, independent sources paint a clear picture of the gap between "it runs" and "it holds."
The Veracode GenAI Code Security Report 2025 tested 100+ models on realistic tasks: in 45% of cases the insecure variant emerged — over 70% for Java, 86% for cross-site scripting. Crucially, larger and newer models did not perform better. This is not a temporary problem the next model generation fixes; it is structural. In parallel, the Stack Overflow Developer Survey 2025 reports that 46% of developers distrust the accuracy of AI output (31% in 2024) and 66% struggle with solutions that are "almost right, but not quite." That "almost right" is easy to miss in a prototype and expensive in production.
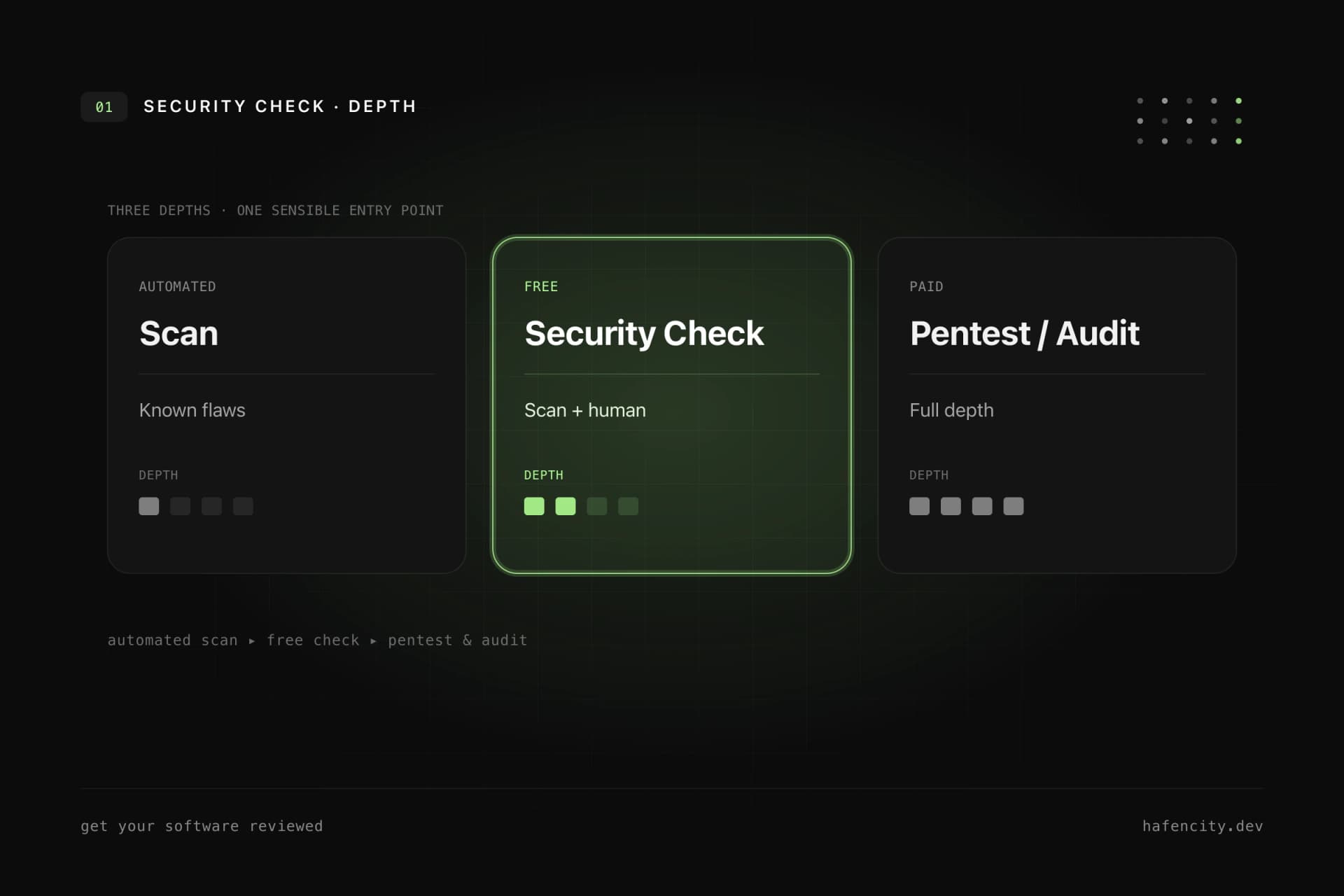
A prototype is not a product — they answer different questions
Both phases matter; the danger only starts when they are mixed up. A prototype is allowed to be unfinished. A product used by customers, processing data or controlling business processes is not. The difference is not how it looks, but which questions the system must answer.
| Dimension | Prototype answers | Production must answer |
|---|---|---|
| Goal | Do users understand the idea? | Does the system hold in daily use? |
| Data | Does the table look plausible? | Is data consistent, secure, transactional? |
| Permissions | Does the happy path work? | Are roles enforced server-side? |
| Errors | Does the demo run? | What happens on bad input or an outage? |
| Quality | Does it look good? | Are core workflows covered by tests? |
| Operations | Does it run locally? | Deployment, monitoring, logs, backups, recovery? |
| Maintenance | Doesn't matter, it's throwaway | Is the code still maintainable in six months? |
The typical weaknesses of AI-generated products rarely appear in the first screenshot. They appear once real users, real data and real processes enter: data models that do not match the business process, validation only in the frontend, inconsistent API contracts, missing transactions, data stored twice. These problems are not AI-specific — but AI produces them faster and at larger volume, because it optimises for visible progress.
Where it breaks under real load
The most expensive problems live below the surface. A beautiful dashboard can show wrong numbers, a modern form can store unsafe data, an app can feel fast in a demo and become unstable under real load. Experienced developers therefore do not check whether a feature visibly runs, but whether it holds:
- whether the architecture fits expected growth
- whether permissions are enforced server-side, not just hidden in the UI
- whether data flows are traceable, consistent and transactional
- whether failure modes are handled in a controlled way instead of ending in the happy path
- whether tests cover the genuinely critical risks
- whether deployment, logging, monitoring, backups and recovery are defined
This is where a good AI prototype separates from production-ready software development. AI is not the problem — unreviewed AI output is. How to address these risks systematically is something we cover in Risks in AI software projects and governance.
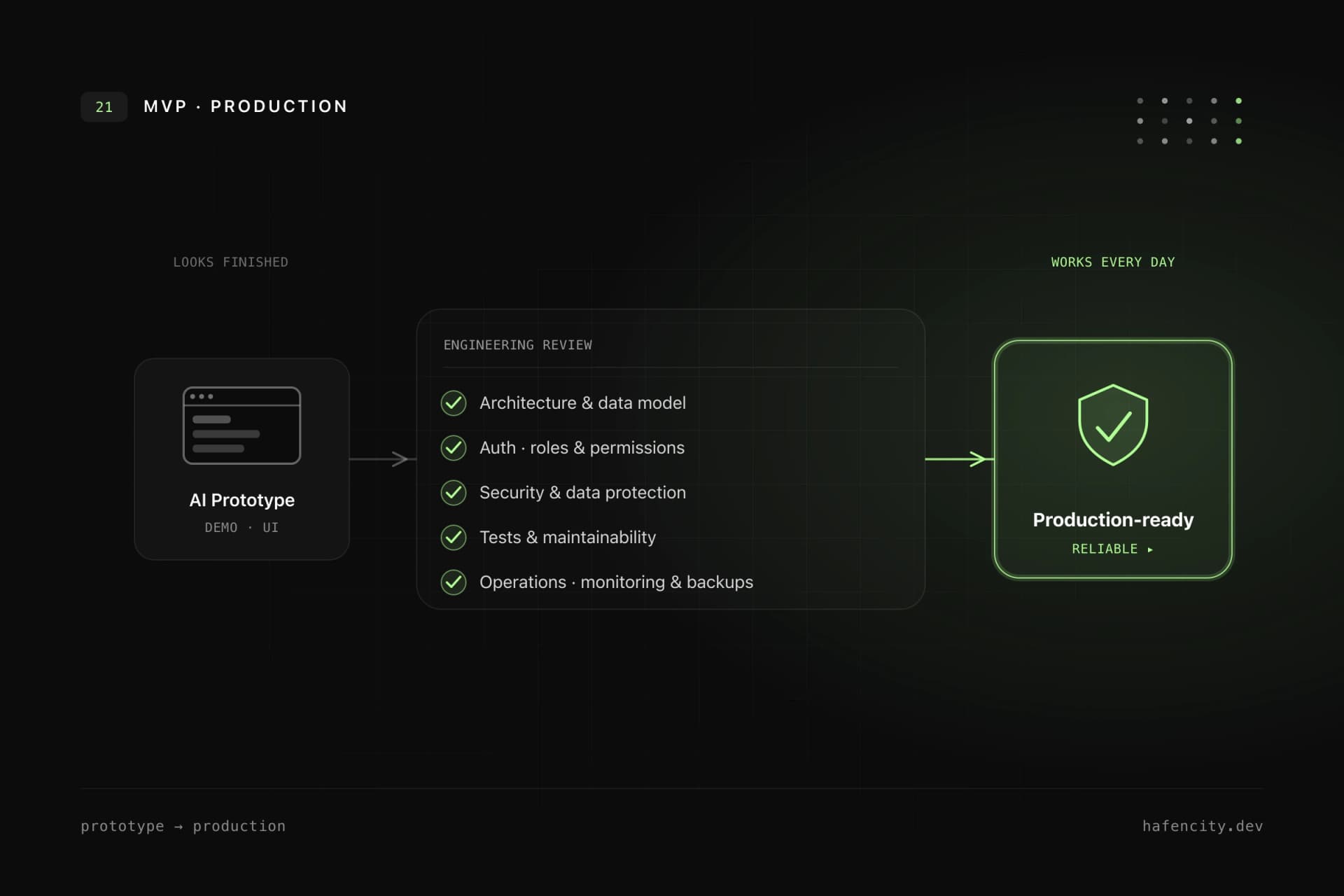
From prototype to production: our approach
The key question is not "Can we finish this?" but "Which parts are reliable, which need rework, which should be redesigned?" A professional entry point follows a clear path — each station decides whether to rescue, refactor or rebuild.
- Code and architecture review: What structure and dependencies exist, and where are the risks?
- Data model and permissions: Are entities, relationships, roles and tenants represented cleanly and enforced server-side?
- Security and privacy: Which data is processed, where is it stored, who can do what — including GDPR implications?
- Tests and CI/CD: Are there tests for core workflows, reproducible builds and clear acceptance criteria?
- Operations and monitoring: Deployment, logging, monitoring, backups, recovery and maintenance.
Not every prototype has to be thrown away. Sometimes the UI is usable but the backend needs restructuring; sometimes the process is good but the data model is wrong; sometimes a targeted rebuild of individual parts is cheaper than months of repair. What such an entry looks like in practice is shown in our software audit with code review.
What hardening costs — and what doing nothing costs
The most expensive path is almost always pushing an unreviewed prototype straight into production. A technical review as an entry point usually sits in the low four figures and gives you a solid basis for decisions. The subsequent hardening is billed by effort — and that depends on how much of the substance holds. For context: per the Freelancer-Kompass 2025, senior day rates in Germany sit at a median above €100 per hour, and often €1,000 per day and more for senior profiles.
Set against that are the costs of doing nothing: a data leak from an open default configuration, a data model that has to be rebuilt at the first real load case, or code no new team member can take over. Why unclean shortcuts end up more expensive is something we cover in Why cheap software often becomes expensive. The honest analysis up front is almost always the cheaper decision.
Next steps
Three questions clarify where your prototype stands faster than any tool duel:
- Data and risk: Which data does the product process, and which features are business-critical?
- Security: Where must permissions be enforced server-side, and which failure modes cause real damage?
- Substance: Is there a traceable data model and tests — or is everything just generated?
If you started with an AI prototype and now want to understand whether it can become a reliable product, a technical review is often the most sensible next step. Take a look at our AI integration or book an intro call directly — together we decide whether stabilisation, refactoring or a clean rebuild is the right path.