
Many software companies still treat SEO mainly as a content task: research keywords, write blog posts, optimize meta titles. None of that is wrong, but it is incomplete — and in 2026 riskier than ever. Search has shifted: according to Pew Research, about 18 percent of all Google searches in March 2025 produced an AI summary, and when one appears, users click a classic result only 8 percent of the time — nearly twice as often (15 percent) when there is no AI answer.
To be found in that environment — or cited as a source by an AI answer — you need more than the right words. A product page can explain a problem perfectly, documentation can answer exactly the questions developers have before an integration. But if those pages are not crawlable, set the wrong canonicals or load too slowly, their potential is wasted. Technical SEO is therefore not a final checklist; it is part of product and website architecture.
Keywords show the language, not the path
Keywords describe how a market searches, but they do not get a page served in the first place. For software companies, intent is layered: executives search for outcomes, cost and risk, product owners for use cases and integrations, developers for API docs, SDKs, webhooks and limits, compliance teams for privacy, roles and certifications. Translating those intents into a durable site structure is the real work — not counting words.
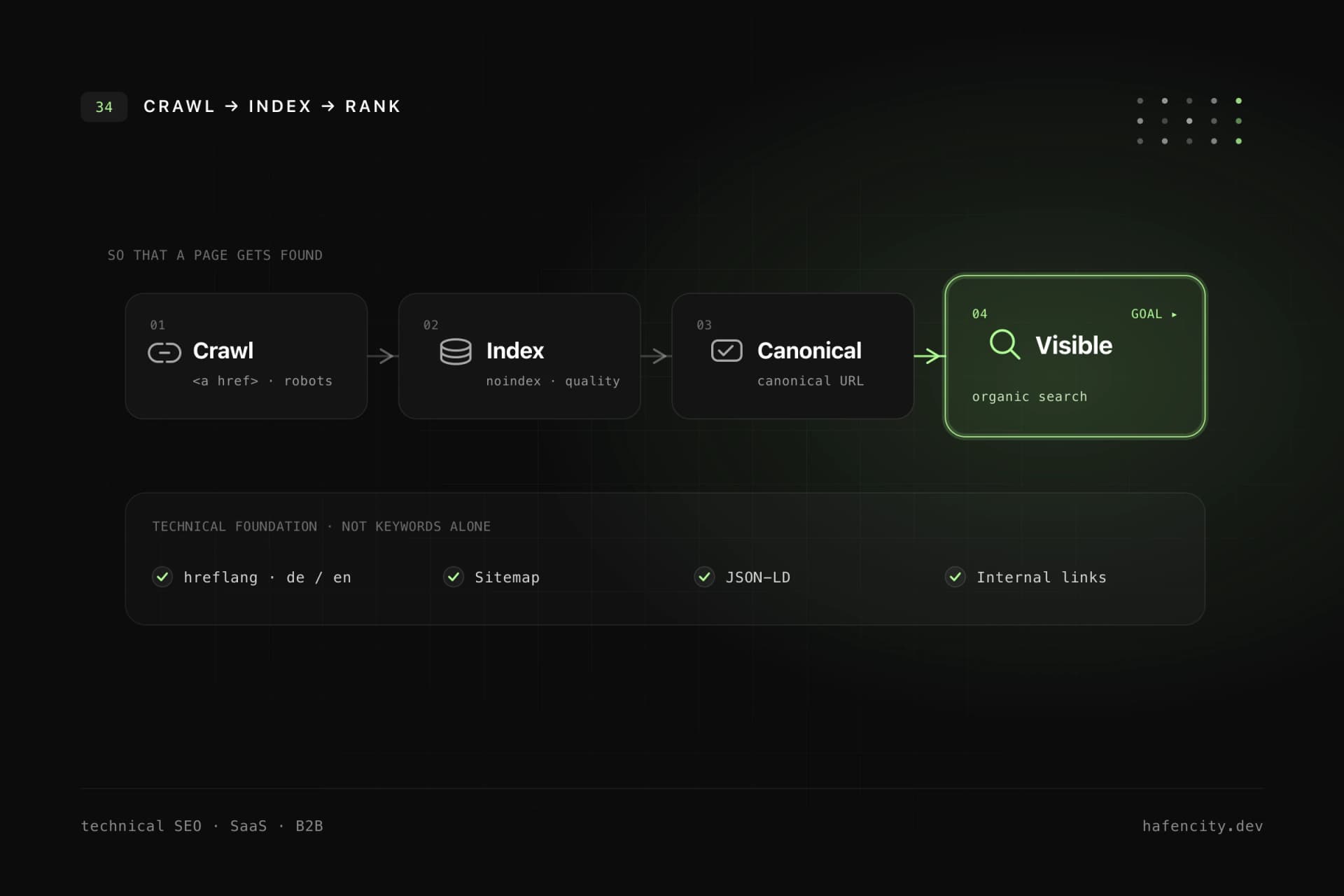
Before any of that sits a technical chain that every keyword depends on. A page has to be discovered (crawled), built correctly (rendered), added to the index (indexed) and finally evaluated (ranked) before it has a chance at all — now including the chance of being cited as a source in an AI answer. If the chain breaks at any link, the best keyword research will not help.
What has changed along this chain recently is more than cosmetic. Three shifts move the priorities for software teams in concrete ways:
| Topic | Before | Today (June 2026) | Source |
|---|---|---|---|
| CWV responsiveness metric | FID | INP < 200 ms (since March 2024) | web.dev |
| FAQ rich results | visible in Search | removed entirely | |
| Click on a result with an AI answer | 15% | 8% | Pew Research |
Crawlability and indexability: reachable is not the same as indexed
Crawling and indexing are two separate steps — and both go wrong quickly on modern software websites. Crawlability describes whether search engines can discover and fetch a page. With JavaScript-heavy frontends, filters, dynamic routes or headless-CMS setups that is not a given: if pricing, docs or integration pages are reachable only through client-side events, or links are built as div or button elements instead of real <a href> links, visibility can suffer unnecessarily. Google's link best practices explicitly state that links should be crawlable as a elements with href attributes.
Indexability is the strategic second question: should this URL be in the index at all? Being crawlable does not automatically mean being indexed — noindex, conflicting canonicals, duplicates or thin content prevent it. The strongest candidates for indexing are pages with distinct search value: product, feature, use-case, integration and comparison pages, public documentation, API references, guides and case studies. Internal search, account areas, thin filter variants, campaign and preview URLs are usually best kept out. Modeling that difference intentionally is half the battle — more on this in our relaunch-without-SEO-loss checklist.
Canonicals, hreflang and structured data: clarity for machines
Software websites create duplicates almost automatically — canonicals, hreflang and structured data turn them into an unambiguous map. /pricing, /de/pricing, tracking parameters, sorted lists, campaign variants and docs versions all produce similar URLs. Google describes canonicalization as selecting the representative URL of a group — if you do not make the choice, Google does, sometimes differently. Three pragmatic rules: every indexable page gets a self-referencing canonical, duplicates point to the main URL, and canonicals, redirects, sitemaps and hreflang must not contradict each other.
Multiple languages raise the stakes. If you serve German and English, put hreflang into the routing: each version references itself and all others, pointing to canonical URLs. Google's guidance on localized versions is clear here. Finally, structured data makes meaning explicit — Google recommends JSON-LD. Important in 2026: FAQ rich results disappeared from Search entirely in June, including the earlier exception for government and health sites. FAQPage markup does no harm but no longer produces visible snippets. Still worthwhile are Organization, Article/BlogPosting, BreadcrumbList and — where requirements are met — Product or SoftwareApplication.
Performance is product quality, not a ranking trick
Performance decides whether users see content, can interact and stay on mobile devices — and it is an official page experience signal. The Core Web Vitals capture this in three measurable values. Since March 2024, INP (Interaction to Next Paint) measures responsiveness and has replaced the older FID metric.
Typical issues on SaaS sites are unoptimized hero images and screenshots, heavy JavaScript bundles from marketing tools, client-rendered content without a clean server- or pre-rendering strategy, and blocking fonts and consent scripts. It is worth separating the marketing website, docs and application technically: public documentation does not need to carry the same JavaScript weight as a logged-in product. How to improve these values deliberately is covered in Core Web Vitals & performance optimization.
Content architecture and internal linking: make the structure visible
Software companies rarely have too little content — they have scattered architecture. Product pages, feature pages, use-case pages, documentation, API references, blog posts and case studies serve different roles and should not compete. A blog post on webhook best practices does not replace an API reference, an API reference does not replace a clear integration page, a feature page does not replace a case study. Good technical SEO makes these roles explicit and connects them sensibly.
Internal links are the connection between content strategy and engineering. Feature pages link to relevant docs and use cases, comparison pages to migration guides and integrations, case studies to the problems solved rather than only to the homepage. Descriptive anchor text matters: "Understand API rate limits" helps users and machines more than "click here". Precisely because AI answers summarize and cite content, a clear, well-linked architecture pays off twice — it makes it easy for crawlers and models to recognize the right page as a source.
What a technical SEO audit should check
A useful audit checks more than titles and keywords; it connects website engineering, CMS, routing and content model. A pragmatic checklist:
- Are all strategically important pages crawlable and reachable via real
<a href>links? - Which pages are indexable, which are intentionally
noindexor blocked? - Do canonicals, redirects, sitemaps and hreflang agree?
- Is structured data valid and does it only describe what users can see?
- Do parameters, filters or campaigns create URL duplicates?
- Are LCP, INP and CLS in the green — on mobile too?
- Is organically important content delivered server-rendered or prerendered?
The key point: technical SEO should be repeatable inside the development process. New pages, languages, docs versions and campaigns should not reshape the search structure by accident every time. How a structured audit measures engineering, performance and accessibility together is described in Quality is measurable.
Next steps
Three questions quickly clarify where your software product stands technically:
- Crawling & index: are all important pages reachable via real links — and is it deliberately decided what gets indexed and what does not?
- Performance: are LCP, INP and CLS in the green, on the phone too?
- Architecture: are docs, blog, product and reference pages connected into clear clusters that search engines and AI answers can recognize as a source?
Unsure where the gaps are? We build technical SEO as a fixed part of development — pragmatically and measurably. Take a look at our web development or book an intro call directly.