
AI writes code in seconds today — and that is both the temptation and the risk. The Veracode GenAI Code Security Report 2025 tested over 100 models across more than 80 coding tasks: 45% of the generated code samples contained at least one OWASP Top 10 vulnerability. Newer or larger models did not do better — the problem is structural, not a question of the next release.
That is not an argument against AI. It is an argument against uncontrolled AI. Use AI naively in software development and you import new risk classes straight into production. Use it with discipline and you gain speed without giving up control. That difference — discipline — is the actual work of an agency.
The new risk classes — with numbers
AI doesn't only shift the pace, it shifts the risk profile. Three effects are evidenced and relevant to anyone shipping AI-generated code to production: insecure code, hallucinated dependencies and rising code churn. A fourth, contractual class joins them: data and IP leakage.
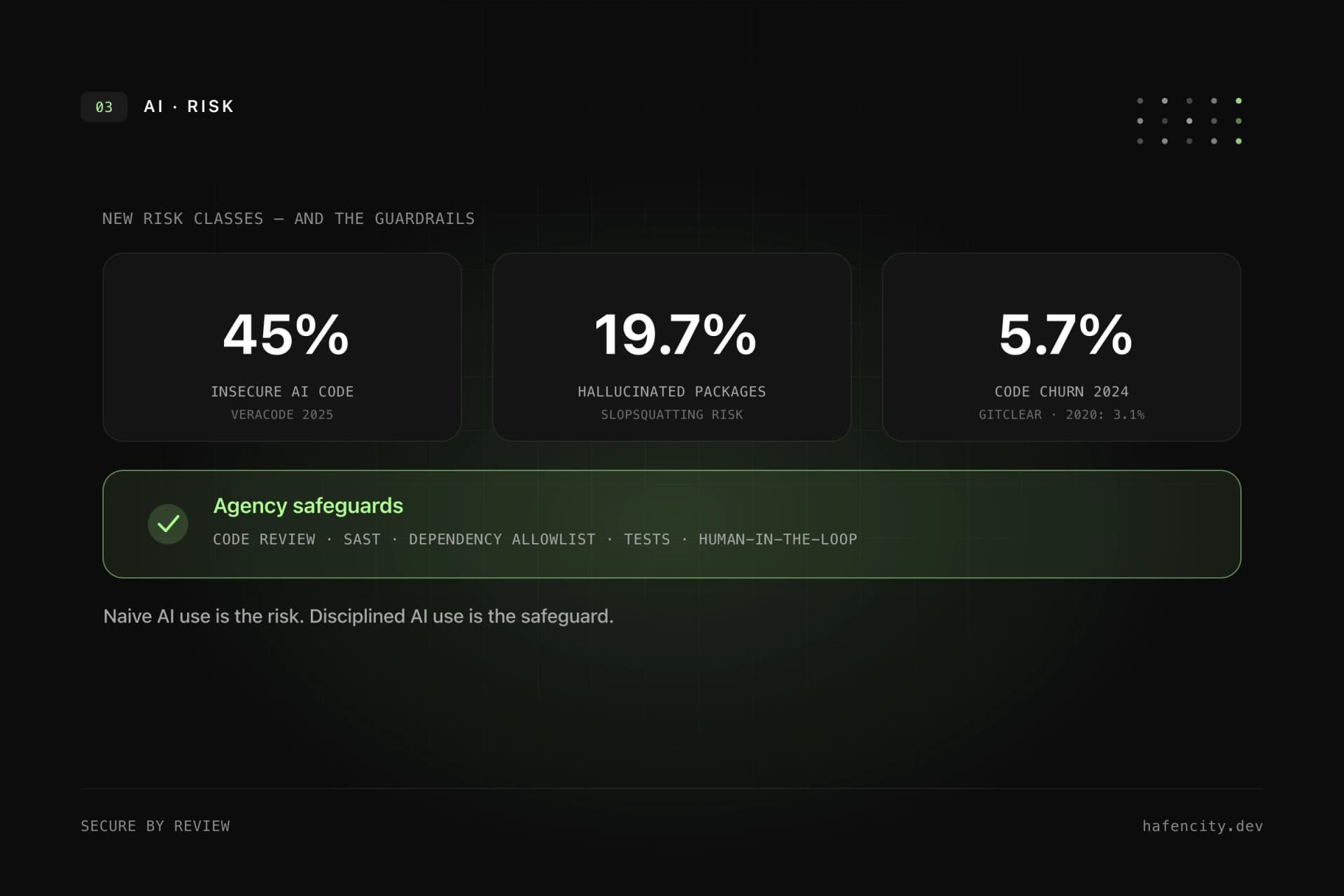
Insecure code is the most direct effect: a 45% vulnerability rate doesn't mean every other line is broken, but that on nearly half of the solved tasks an exploitable gap remained. Hallucinated packages are subtler: models invent library names that sound plausible but don't exist. Per a study summarised by BleepingComputer, around 19.7% of samples referenced such a package — and because the names recur, an attacker can register them and slip in malicious code ("slopsquatting"). Code churn, finally, is the quietest signal: per GitClear, more code is reverted shortly after being written and copied more often than cleanly refactored — an early indicator of maintenance load.
| Risk class | What happens | Finding | Countermeasure |
|---|---|---|---|
| Insecure code | OWASP flaws in the output | 45% of samples (Veracode 2025) | review + SAST/security scan |
| Hallucinated packages | invented dependencies | 19.7% of samples (slopsquatting) | dependency allowlist + pinning |
| Code churn / tech debt | copied not refactored | 3.1% → 5.7% (GitClear) | tests, CI gates, architecture |
| Data / IP leakage | code to external models | GDPR & EU AI Act | clear data boundaries |
Why naive AI use bites in production
The most dangerous moment isn't the prototype, it's the day unreviewed AI code goes live. AI is excellent at producing something that is almost right — and "almost right" is the most expensive category in production. In the Stack Overflow Developer Survey 2025, 66% of developers cite exactly that as their biggest frustration; for around 45%, debugging AI code takes longer than writing it themselves. The speed at the start hides the cost at the end.
This dynamic is measurable at team level too. The DORA report 2025 confirms, on one hand, that AI amplifies productivity — more tasks completed, more pull requests merged. On the other, it shows a negative relationship between AI adoption and delivery stability as long as there is no strong foundation of automated tests, version control and fast feedback. AI amplifies what's already there: where discipline is missing, it amplifies instability; where discipline exists, it amplifies quality. We described that same logic in more depth in Risks in AI software projects and governance.
The safeguard: the stack an agency puts in between
Every single risk class has an established countermeasure — the craft is running them as a mandatory layer, not a good intention. An agency that takes AI seriously treats AI output like a new team member's code: useful, but never merged unreviewed. Above it sits a governance layer enforcing one simple rule — AI is a tool, the human decides and is accountable.
Concretely, that is six measures working together:
- Peer code review: no AI-generated line enters the main branch without human sign-off. That catches both the 45% flaws and subtle logic errors.
- SAST & security scan in CI: automated OWASP checks on every merge, so security doesn't depend on the day.
- Dependency allowlist & pinning: only approved, version-pinned packages — the direct answer to slopsquatting. Snyk recommends verified sources and lockfiles as the standard here.
- Tests & CI gates: automated tests are the foundation DORA shows decides stability — they turn speed into reliable releases.
- Data & secret boundaries: a defined tool list, no proprietary code to external models, no secrets in prompts.
- License & IP checks: the provenance and licensing of the output are clarified before it ships.
How these practices come together in a structured review is shown in our software audit & code review.
Data, IP and the EU AI Act
The moment proprietary code leaves for an external model, a technical question becomes a legal one. Two things need clarifying: what happens to the data you send the model — and who owns the output. In practice that means drawing a clear line: which repositories AI tools may see and which they may not; whether the provider trains on your data; and whether secrets or customer data come anywhere near a prompt at all.
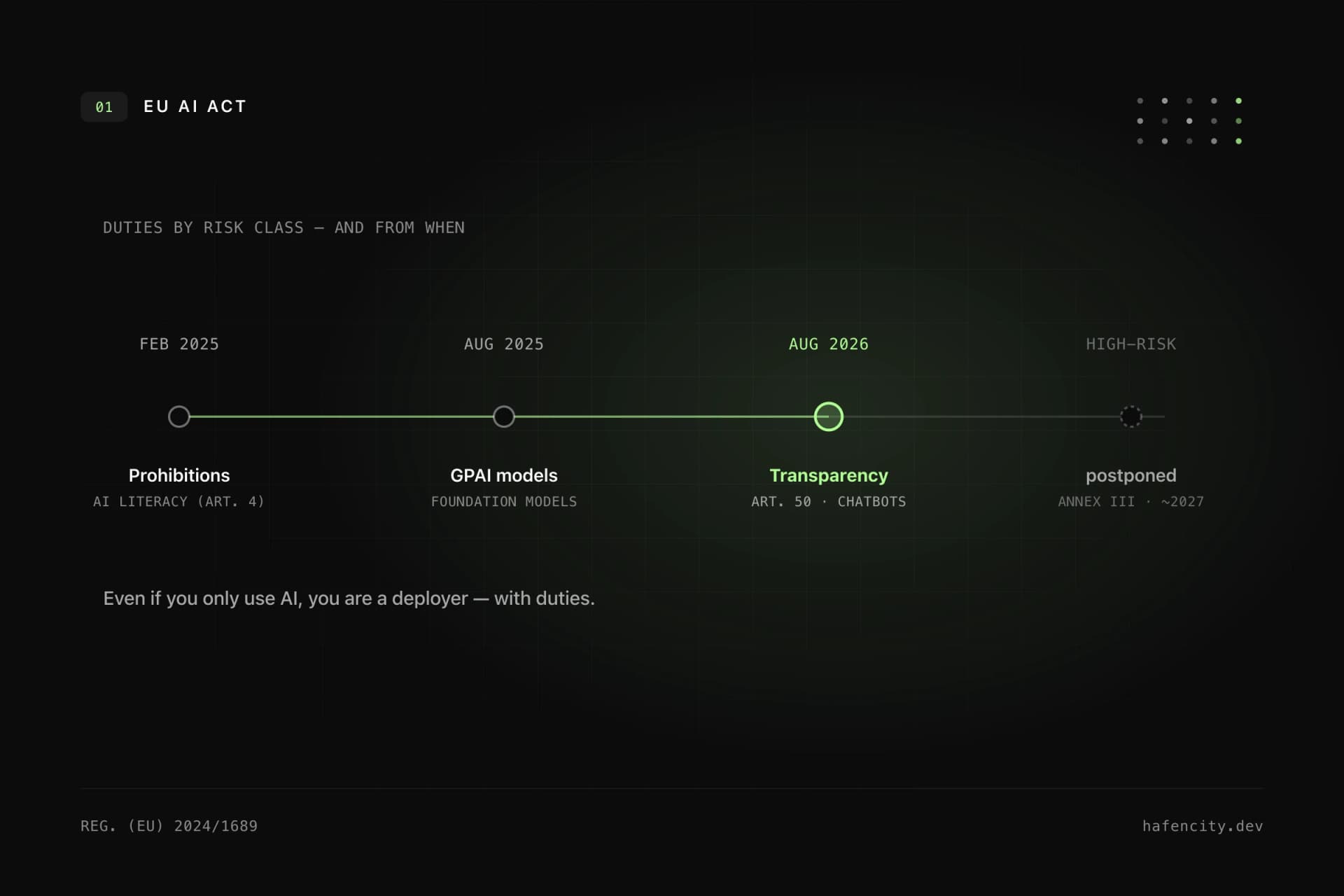
Then there is the regulatory frame. The EU AI Act has been in force since 1 August 2024 and applies in staggered phases; depending on use, documentation and transparency obligations arise. For code generation itself this rarely means dramatic hurdles, but it does set a clear expectation: traceable processes, documented tool use, clean data boundaries. An agency that uses AI professionally has drawn those boundaries — contractually and technically — anyway.
How to recognise a disciplined AI agency
The difference between a professional and a "vibe coder" shows not in speed, but in how they answer the question about safeguards. Ask specifically — the answers are a reliable filter:
- Does every AI-generated line go through review, or just "the important ones"?
- Do security scans run automatically in CI, or occasionally by hand?
- Is there a dependency allowlist and lockfiles against hallucinated packages?
- Are tests a mandatory gate that blocks merges?
- Are there documented data boundaries — which code may see which tool?
Anyone who answers "of course, that's how we work" with concrete examples uses AI for what it is: an accelerator within solid engineering. Anyone who deflects or talks only about speed is shifting the risk onto your product. For more on how AI embeds cleanly into day-to-day development, see AI coding with Codex and Claude, as well as our sibling posts How an agency ships faster with AI and Will AI replace your software agency?.
Next steps
Three questions quickly show whether your AI code is safeguarded:
- Review: does every AI-generated line pass a human code review before it goes live?
- Supply chain: does a dependency allowlist with pinning protect against hallucinated or slipped-in packages?
- Data boundaries: is it clearly regulated which code each AI tool may see — and what happens to your data?
If any of these stays unanswered, an outside look pays off. We use AI productively in projects — with exactly these safeguards. Take a look at our AI integration and development, or book an intro call directly.